背景介绍—
Web项目中,使用一个适合的字体能给用户带来良好的体验。但是字体文件这么多,如果设计师或者开发人员想要查询字体,只能一个个打开,非常影响工作效率。我负责的平台项目刚好需要实现一个功能,能够支持根据固定文字以及用户输入预览字体。在实现这一功能的过程中主要解决两个问题:
中文字体体积太大导致加载时间过长 字体加载完成前不展示预览内容
现在将问题的解决以及我的思考总结成文。

使用web自定义字体—
在聊这两个问题之前,我们先简述怎样使用一个Web自定义字体。要想使用一个自定义字体,可以依赖CSSFontsModuleLevel3定义的@font-face>@font-face{font-family:"webfontFamily";/*名字任意取*/src:url('webfont.eot');url('web.eot?#iefix')format("embedded-opentype"),url("webfont.woff2")format("woff2"),url("webfont.woff")format("woff"),url("webfont.ttf")format("truetype");font-style:normal;font-weight:normal;}.webfont{font-family:webfontFamily;/*@font-face里定义的名字*/}
由于woff2、woff、ttf>@font-face{font-family:"webfontFamily";/*名字任意取*/src:url("webfont.woff2")format("woff2"),url("webfont.woff")format("woff"),url("webfont.ttf")format("truetype");font-style:normal;font-weight:normal;}
有了@font-face规则,我们只需要将字体源文件上传至cdn,让@font-face规则的url>
但这么做我们可以明显发现一个问题,字体体积太大导致的加载时间过长。我们打开浏览器的Network面板查看:

可以看到字体的体积为5.5MB,加载时间为5.13s。而夸克平台很多的中文字体大小在20~40MB之间,可以预想到加载时间会进一步增长。如果用户还处于弱网环境下,这个等待时间是不能接受的。
中文字体体积太大导致加载时间过长—
分析原因
那么中文字体相较于英文字体体积为什么这么大,这主要是两个方面的原因:
中文字体包含的字形数量很多,而英文字体仅包含26个字母以及一些其他符号。 中文字形的线条远比英文字形的线条复杂,用于控制中文字形线条的位置点比英文字形更多,因此数据量更大。
我们可以借助于opentype.js,统计一个中文字体和一个英文字体在字形数量以及字形所占字节数的差异:
| 字体名称 | 字形数 | 字形所占字节数 |
|---|---|---|
| FZQingFSJW_Cu.ttf | 8731 | 4762272 |
| JDZhengHT-Bold.ttf | 122 | 18328 |
夸克平台字体预览需要满足两种方式,一种是固定字符预览,另一种是根据用户输入的字符进行预览。但无论哪种预览方式,也仅仅会使用到该字体的少量字符,因此全量加载字体是没有必要的,所以我们需要对字体文件做精简。
如何减小字体文件体积
unicode-range属性一般配合@font-face>
CSSunicode-range特定字符使用font-face自定义字体
实际上的精简并没有这么简单,因为一个字体文件由许多 在讨论 上面的结构限于字体文件只包含一种字体,且字形轮廓是基于 >偏移表(offset> >表记录(table> 对于一个字体文件,无论其字形轮廓是TrueType格式还是基于PostScript语言的CFF格式,其必须包含的表有 将字体文件转为 前文我们说到紧跟在 在这一步会根据 根据规范,索引 上述表格中Offset字段值的单位是字节,但是具体的字节数取决于字体 但是仅仅知道所有字形的偏移量还不够,我们没办法认出哪个字形才是我们需要的。假设我需要 而一个字形的数据结构以 在字体的定义中,轮廓是由一个个位置点构成的,并且每个位置点具有编号,这些编号从 在 另外,在提取坐标信息时,除了第一个位置点,其他位置点的坐标值并不是绝对值,例如第一个点的坐标为 因为一个字体涉及的表实在太多,并且每个表的数据结构也不一样。这里无法一一列举 在使用了TrueType轮廓的字体中,每个字形都提供了 在这一步会重新计算字体文件的大小,并且更新 在了解了 对于固定的预览内容,我们也可以先生成字体文件保存在CDN上,但是这个方式的缺点在于如果CDN不稳定就会造成字体加载失败。如果用上面的方法,每一个截取后的字体以 对于固定预览内容我们可以预先生成好分割后的字体,对于用户输入的动态预览内容,我们当然也可以按照这个流程: 获取输入->截取字形->上传CDN->生成@font-face->插入页面 按照这个流程来客户端需要请求两次才能获取字体资源(别忘了在 获取位置信息以及生成 下面附上字体截取后文件大小和加载速度对比表格。可以看出,相较于全量加载,对字体进行截取后加载速度快了 这是在实现预览功能过程中的第二个问题。 在浏览器的字体显示行为中存在 字体的显示策略和 第一种策略是 第二种策略是 两种不同策略的应用:GoogleFontsFOIT 汉仪字库FOUT 在夸克项目中,我希望的效果是字体加载完成前不展示预览内容, 查阅资料得知,CSSFontLoadingAPI在 先看看它们的兼容性: 又是IE,IE没有用户不用管 我们可以通过 >family >source 字体来源,可以是一个 >descriptors style: weight: stretch: display: unicodeRange: variant: featureSettings: 构造出一个 使用方法如下: 因此,在客户端我们可以先设置文字内容的CSS为 本文介绍了在开发字体预览功能时遇到的问题和解决方案,限于 本次工作的回顾和总结过程中,也在思考更好的实现,如果你有建议欢迎和我交流。同时文章的内容是我个人的理解,存在错误难以避免,如果发现错误欢迎指正。 感谢阅读!fontmin是一个纯JavaScript>//伪代码consttext='字体预览'constunicodes=text.split('').map(str=>str.charCodeAt(0))constfont=loadFont(fontPath)font.glyf=font.glyf.map(g=>{//根据unicodes获取对应的字形})表(table)构成,这些表之间是存在关联的,例如maxp表记录了字形数量,loca表中存储了字形位置的偏移量。同时字体文件以offsettable(偏移表)开头,offsettable记录了字体所有表的信息,因此如果我们更改了glyf>fontmin>
TrueType格式(决定sfntVersion的取值)的情况,因此偏移表会从字体文件的0字节开始。如果字体文件包含多个字体,则每种字体的偏移表会在>Type Name Description uint32 sfntVersion 0x00010000 uint16 numTables Numberoftables uint16 searchRange (Maximumpowerof2<=numTables)x16. uint16 entrySelector Log2(maximumpowerof2<=numTables). uint16 rangeShift NumTablesx16-searchRange. Type Name Description uint32 tableTag Tableidentifier uint32 checkSum CheckSumforthistable uint32 offset OffsetfrombeginningofTrueTypefontfile uint32 length Lengthofthistable cmap、head、hhea、htmx、maxp、name、OS/2、post。如果其字形轮廓是TrueType格式,还有cvt、fpgm、glyf、loca、prep、gasp六张表会被用到。这六张表除了glyf和loca>fontmin内部使用了fonteditor-core,核心的字体处理交给这个依赖完成,fonteditor-core>
ArrayBuffer>offsettable(偏移表)之后的结构就是tablerecord(表记录),而多个tablerecord叫做TableDirectory。fonteditor-core会先读取原字体的TableDirectory,由上文表记录的结构我们知道,每一个tablerecord有四个字段,每个字段占4个字节,因此可以很方便的利用DataView>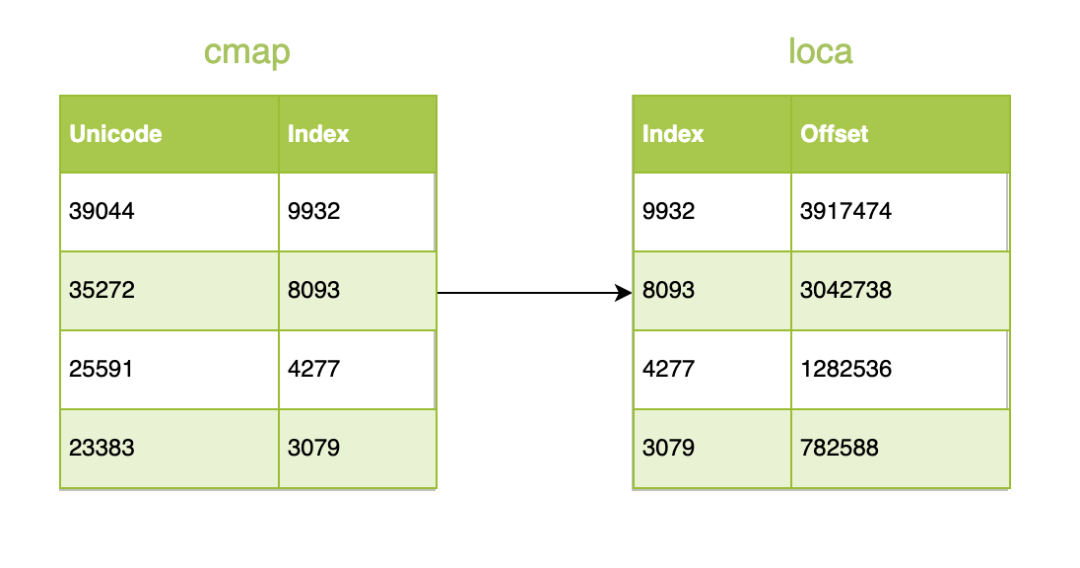
TableDirectory记录的偏移和长度信息读取表数据。对于精简字体来说,glyf表的内容是最重要的,但是glyf的tablerecord仅仅告诉了我们glyf表的长度以及glyf表相对于整个字体文件的偏移量,那么我们如何得知glyf表中字形的数量、位置以及大小信息呢?这需要借助字体中的maxp表和loca(glyphslocation)表,maxp表的numGlyphs字段值指定了字形数量,而loca表记录了字体中所有字形相对于glyf>GlyphIndex Offset GlyphLength 0 0 100 1 100 150 2 250 0 ... ... ... n-1 1170 120 extra 1290 0 0指向缺失字符(missingcharacter),也就是字体中找不到某个字符时出现的字符,这个字符通常用空白框或者空格表示,当这个缺失字符不存在轮廓时,根据loca表的定义可以得到loca[n]=loca[n+1]。我们可以发现上文表格中多出了extra一项,这是为了计算最后一个字形loca[n-1]>head表的indexToLocFormat字段取值,当此值为0时,Offset100等于200个字节,当此值为1时,Offset100等于100个字节,这两种不同的情况对应于字体中的Shortversion和Longversion。字体预览这四个字形,而字体文件有一万个字形,同时我们通过loca表得知了所有字形的偏移量,但这一万里面哪四个数据块代表了字体预览四个字符呢?因此我们还需要借助cmap表来确定具体的字形位置,cmap表里记录了字符代码(unicode)到字形索引的映射,我们拿到对应的字形索引后,就可以根据索引获得该字形在glyf>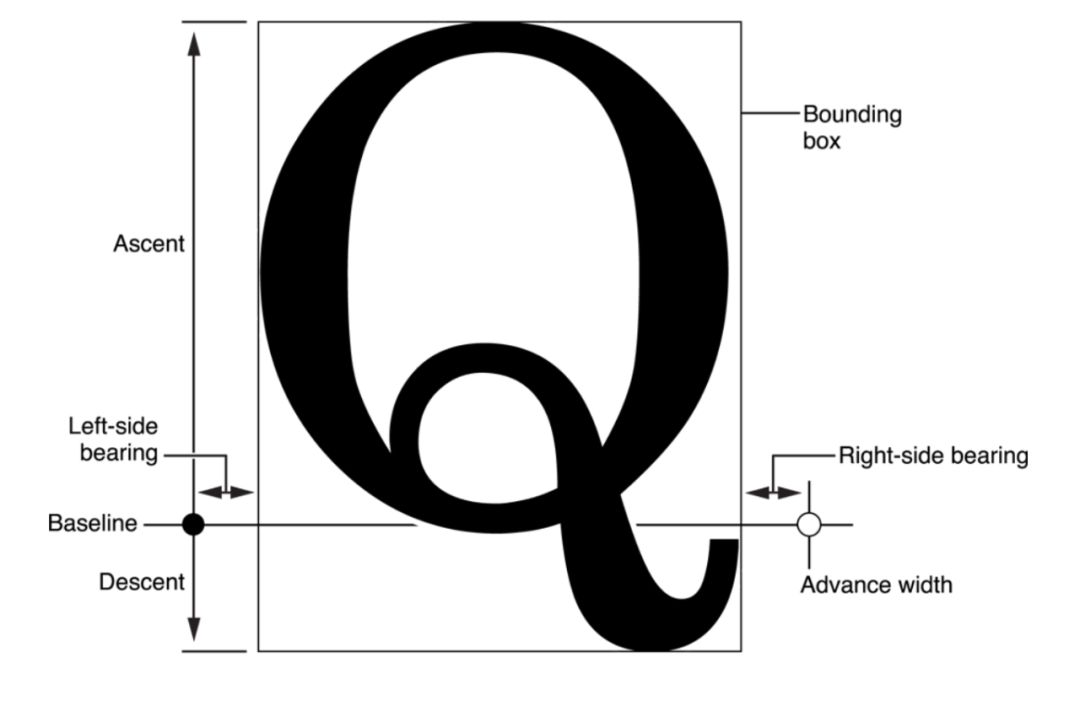
GlyphHeaders>Type Name Description int16 numberOfContours thenumberofcontours int16 xMin Minimumxforcoordinatedata int16 yMin Maximumyforcoordinatedata int16 xMax Minimumxforcoordinatedata int16 yMax Maximumxforcoordinatedata numberOfContours字段指定了这个字形的轮廓数量,紧跟在GlyphHeaders后面的数据结构为GlyphTable。0开始按升序排列。因此我们读取指定的字形就是读取GlyphHeaders>GlyphTable中,存放了每个轮廓的最后一个位置点编号构成的数组,从这个数组中就可以求得这个字形一共存在几个位置点。例如这个数组的值为[3,6,9,15],可以得知第四个轮廓上最后一个位置点的编号是15,那么这个字形一共有16个位置点,所以我们只需要以16为循环次数进行遍历访问ArrayBuffer就可以得到每个位置点的坐标信息,从而提取出了我们想要的字形,这也就是fontmin>[100,100],第二个读取到的值为[200,200],那么该点位置坐标并不是[200,200],而是基于第一个点的坐标进行增量,因此第二点的实际坐标为[300,300]fonteditor-core>xMin、xMax、yMin和yMax的值,这四个值也就是下图的BoundingBox。除了这四个值,还需要advanceWidth和leftSideBearing两个字段,这两个字段并不在glyf表中,因此在截取字形信息的时候无法获取。在这个步骤,fonteditor-core会读取字体的hmtx>
偏移表(Offsettable)和表记录(Tablerecord)有关的值,然后依次将偏移表、表记录、表数据写入文件中。有一点需要注意的是,在写入表记录时,必须按照表名排序进行写入。例如有四张表分别是prep、hmtx、glyf、head、则写入的顺序应为glyf->head->hmtx->prep,而表数据没有这个要求。fonteditor-core在截取字体的过程中只会对前文提到的十四张表进行处理,其余表丢弃。每个字体通常还会包含vhea和vmtx两张表,它们用于控制字体在垂直布局时的间距等信息,如果用fontmin>右边为截取后):
fontmin的原理后,我们就可以愉快的使用它啦。服务器接受到客户端发来的请求后,通过fontmin截取字体,fontmin会返回截取后的字体文件对应的Buffer,别忘了@font-face规则中字体路径是支持base64格式的,因此我们只需要将Buffer转为base64格式嵌入在@font-face中返回给客户端,然后客户端将该@font-face以CSS形式插入<head></head>>base64字符串形式存在,则可以在服务端做一个缓存,就没有这个问题。利用fontmin>constFontmin=require('fontmin')constPromise=require('bluebird')asyncfunctionextractFontData(fontPath){constfontmin=newFontmin().src('./font/senty.ttf').use(Fontmin.glyph({text:'字体预览'})).use(Fontmin.ttf2woff2()).dest('./dist')awaitPromise.promisify(fontmin.run,{context:fontmin})()}extractFontData()@font-face插入页面后才会去真正请求字体),并且截取字形和上传CDN这两步时间消耗也比较长,有没有更好的办法呢?我们知道字形的轮廓是由一系列位置点确定的,因此我们可以获取glyf表中的位置点坐标,通过SVG>SVG是一种强大的图像格式,可以使用CSS和JavaScript与它们进行交互,在这里主要应用了path>path标签我们可以借助opentype.js完成,客户端得到输入字形的path元素后,只需要遍历生成SVG>减小字体文件体积的优势
145>fontmin是支持生成woff2文件的,但是官方文档并没有更新,最开始我使用的woff文件,但是woff2>字体名称 大小 时间 HanyiSentyWoodcut.ttf 48.2MB 17.41s HanyiSentyWoodcut.woff 21.7KB 0.19s HanyiSentyWoodcut.woff2 12.2KB 0.12s 字体加载完成前不展示预览内容—
阻塞期和交换期两个概念,以Chrome为例,在字体加载完成前,会有一段时间显示空白,这段时间被称为阻塞期。如果在阻塞期内仍然没有加载完成,就会先显示后备字体,进入交换期,等待字体加载完成后替换。这就会导致页面字体出现闪烁,与我想要的效果不符。而font-display属性控制浏览器的这个行为,是否可以更换font-display>font-display
BlockPeriod SwapPeriod block Short Infinite swap None Infinite fallback ExtremelyShort Short optional ExtremelyShort None font-display的取值有关,浏览器默认的font-display值为auto,它的行为和取值block>FOIT(FlashofInvisibleText),FOIT>FOUT(FlashofUnstyledText),FOUT会指示浏览器使用后备字体直至自定义字体加载完成,对应的取值为swap。FOIT策略最为接近。但是FOIT文本内容不可见的最长时间大约是3s,如果用户网络状况不太好,那么3s过后还是会先显示后备字体,导致页面字体闪烁,因此font-display>JavaScript>FontFace、FontFaceSet

FontFace构造函数构造出一个FontFace>constfontFace=newFontFace(family,source,descriptors)CSS属性font-family>url或者ArrayBufferoptionalfont-stylefont-weightfont-stretchfont-display>(这个值可以设置,但不会生效)@font-face规则的unicode-rangesfont-variantfont-feature-settingsfontFace后并不会加载字体,必须执行fontFace的load方法。load方法返回一个promise,promise的resolve值就是加载成功后的字体。但是仅仅加载成功还不会使这个字体生效,还需要将返回的fontFace添加到fontFaceSet。/***@param{string}path字体文件路径*/asyncfunctionloadFont(path){constfontFaceSet=document.fontsconstfontFace=awaitnewFontFace('fontFamily',`url('${path}')format('woff2')`).load()fontFaceSet.add(fontFace)}opacity:0,等待awaitloadFont(path)执行完毕后,再将CSS设置为opacity:1,>最后总结—
OpenType规范条目很多,在介绍fontmin原理部分,仅描述了对glyf>参考—
文章为用户上传,仅供非商业浏览。发布者:Lomu,转转请注明出处: https://www.daogebangong.com/articles/detail/Practice%20of%20web%20Chinese%20font%20performance%20optimization.html
 支付宝扫一扫
支付宝扫一扫 
评论列表(196条)
测试