随着数字化时代的发展,PDF(可移植文档格式)已经成为一种广泛使用的文件格式。然而,有时候我们需要从PDF文件中提取文本,以便进行编辑、复制或搜索。为了满足这一需求,文字识别技术应运而生。本文将介绍文字识别技术在PDF中的应用,并提供一种方法。

文字识别技术(OCR)是一种通过计算机程序将印刷或手写文本转换为可编辑、可搜索的电子文本的技术。OCR技术通过扫描文档图像,并使用图像处理和模式识别算法来识别文字的形状和结构。

PDF文件通常包含扫描过的图像或已转换为图像的文本。使用文字识别技术可以将这些图像转换为可编辑的文本,并具备以下优势:文字识别技术使得PDF文件中的文本可编辑。我们可以对文本进行修改、添加或删除,从而灵活地进行编辑工作。
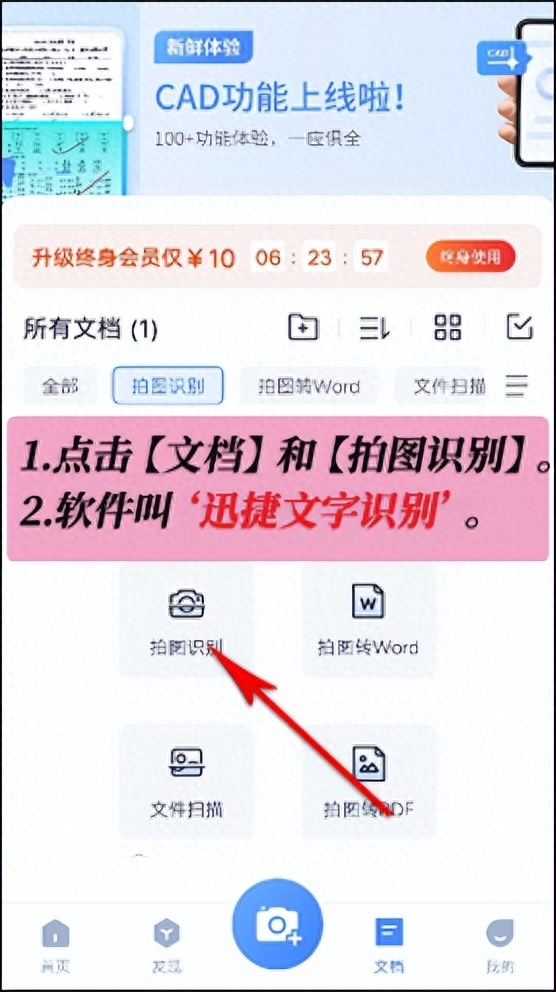
通过文字识别技术,我们可以从PDF文件中复制文本并粘贴到其他文档中,从而提高工作效率。文字识别技术使得PDF文档中的内容可以被搜索引擎索引和识别。我们可以通过关键词搜索来快速定位所需的信息。
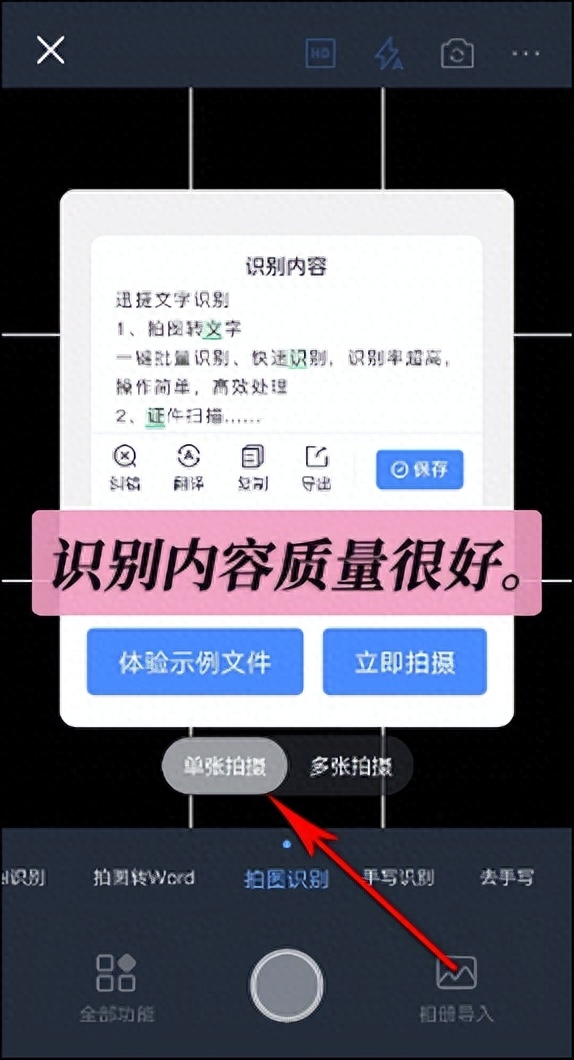
以下是一种简单的方法来在PDF中使用文字识别技术:下载和安装一款优秀的OCR软件。打开OCR软件并导入要识别的PDF文件。软件将自动扫描文档图像并将其转换为可编辑的文本。检查文本识别结果并进行必要的编辑。OCR技术在处理扭曲、低分辨率或手写文本时可能会产生一些误差,所以需要手动校正。保存识别后的文件并导出为其他格式,如Word或纯文本文件。
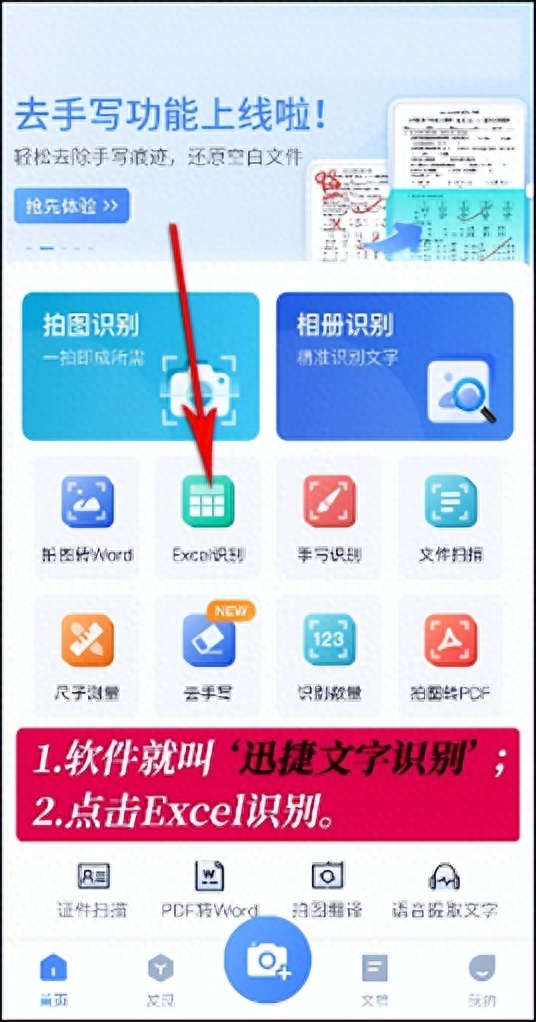
文字识别技术为我们从PDF文件中提取文本带来了便利和效率。通过将扫描的图像转换为可编辑的文本,文字识别技术为我们提供了更多的选择和操作。无论是在个人生活中还是工作场景中,文字识别技术都能发挥重要作用。因此,学会使用文字识别技术是必不可少的技能。
文章为用户上传,仅供非商业浏览。发布者:Lomu,转转请注明出处: https://www.daogebangong.com/articles/detail/PDF-zen-me-wen-zi-shi-bie-shi-shi-kan-zhe-me-zuo.html
 支付宝扫一扫
支付宝扫一扫 
评论列表(196条)
测试