前言
Html能够通过Html标签来为文字设置样式,让TextView显示富文本信息,其只支持部分标签不是全部,具体支持哪些标签将分析中揭晓。
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
TextView textView = (TextView) findViewById(R.id.tv_html);
String htmlString =
'<font color='#ff0000'>颜色</font><br/>' +
'<a >链接</a><>br/>' +
'<big>大字体</big><br/>'+
'<small>小字体</small><br/>'+
'<b>加粗</b><br/>'+
'<i>斜体</i><br/>' +
'<h1>标题一</h1>' +
'<h2>标题二</h2>' +
'<img src='ic_launcher'/>' +
'<blockquote>引用</blockquote>' +
'<div>块</div>' +
'<u>下划线</u><br/>' +
'<sup>上标</sup>正常字体<sub>下标</sub><br/>' +
'<u><b><font color='@holo_blue_light'><sup><sup>组</sup>合</sup><big>样式</big><sub>字<sub>体</sub></sub></font></b></u>';
textView.setText(Html.fromHtml(htmlString));
}
由此可以看出Html还是比较强大的一个东西呀!
使用Html.toHtml方法能够将带有样式效果的Spanned文本对象生成对应的Html格式,标签内的字符会被转译成,下面为WebView显示效果,部分效果与上面TextView显示的效果有差异,代码如下:
webView.loadData(Html.toHtml(Html.fromHtml(htmlString)),'text/html', 'utf-8');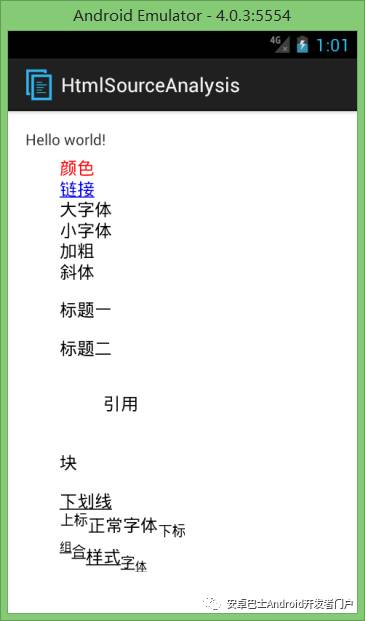
显示效果还是有点差距的,用的是安卓4.0.3的手机系统,所以可能显示上有点问题,不过应该不影响大家区分。重点毕竟不在这里,大家继续往下看原理吧!
原理分析
/**
* 为<img>标签提供图片检索功能
*/
public static interface ImageGetter {
/**
* 当HTML解析器解析到<img>标签时,source参数为标签中的src的属性值,
* 返回值必须为Drawable;如果返回null则会使用小方块来显示,如前面所见,
* 并需要调用Drawable.setBounds()方法来设置大小,否则无法显示图片。
* @param source:
*/
public Drawable getDrawable(String source);
}
/**
* HTML标签解析扩展接口
*/
public static interface TagHandler {
/**
* 当解析器解析到本身不支持或用户自定义的标签时,该方法会被调用
* @param opening:标签是否打开
* @param tag:标签名
* @param output:截止到当前标签,解析到的文本内容
* @param xmlReader:解析器对象
*/
public void handleTag(boolean opening, String tag,
Editable output, XMLReader xmlReader);
}
private Html() { }
/**
* 返回样式文本,所有<img>标签都会显示为一个小方块
* 使用TagSoup库处理HTML
* @param source:带有html标签字符串
*/
public static Spanned fromHtml(String source) {
return fromHtml(source, null, null);
}
/**
* 可传入ImageGetter来获取图片源,TagHandler添加支持其他标签
*/
public static Spanned fromHtml(String source, ImageGetter imageGetter,
TagHandler tagHandler) {
.....
}
/**
* 将带样式文本反向解析成带Html的字符串,注意这个方法并不是还原成fromHtml接收的带Html标签文本
*/
public static String toHtml(Spanned text) {
StringBuilder out = new StringBuilder();
withinHtml(out, text);
return out.toString();
}
/**
* 返回转译标签后的字符串
*/
public static String escapeHtml(CharSequence text) {
StringBuilder out = new StringBuilder();
withinStyle(out, text, 0, text.length());
return out.toString();
}
/**
* 懒加载HTML解析器的Holder
* a) zygote对其进行预加载
* b) 直到需要的时候才加载
*/private static class HtmlParser {
private static final HTMLSchema schema = new HTMLSchema();
}
。。。。fromHtml(String source, ImageGetter imageGetter,TagHandler tagHandler):
Html类主要方法就4个,功能也简单,生成带样式的fromHtml方法最终都是调用重载3个参数的方法。
public static Spanned fromHtml(String source, ImageGetter imageGetter,
TagHandler tagHandler) {
//初始化解析器
Parser parser = new Parser();
try {
//配置解析Html模式
parser.setProperty(Parser.schemaProperty, HtmlParser.schema);
} catch (org.xml.sax.SAXNotRecognizedException e) {
throw new RuntimeException(e);
} catch (org.xml.sax.SAXNotSupportedException e) {
throw new RuntimeException(e);
} //初始化真正的解析器
HtmlToSpannedConverter converter =
new HtmlToSpannedConverter(source, imageGetter, tagHandler,parser);
return converter.convert();
}源代码中并没有包含Parser对象,而是必须导入org.ccil.cowan.tagsoup.Parser,HTML解析器是使用Tagsoup库来解析HTML标签,Tagsoup是兼容SAX的解析器,我们知道对XML常见的的解析方式还有DOM、Android系统中还使用PULL解析与SAX同样是基于事件驱动模型,使用tagsoup是因为该库可以将HTML转化为XML,我们都知道HTML有时候并不像XML那样标签都需要闭合,例如也是一个有效的标签,但是在XML中则是不良格式。详情可见官方网站,但是好像没有开发文档,这里就不详细说明,只关注SAX解析过程。
HtmlToSpannedConverter原理
class HtmlToSpannedConverter implements ContentHandler {
private static final float[] HEADER_SIZES = {
1.5f, 1.4f, 1.3f, 1.2f, 1.1f, 1f,
};
private String mSource;
private XMLReader mReader;
private SpannableStringBuilder mSpannableStringBuilder;
private Html.ImageGetter mImageGetter;
private Html.TagHandler mTagHandler;
public HtmlToSpannedConverter(
String source, Html.ImageGetter imageGetter, Html.TagHandler tagHandler,
Parser parser) {
mSource = source;//html文本
mSpannableStringBuilder = new SpannableStringBuilder();//用于存放标签中的字符串
mImageGetter = imageGetter;//图片加载器
mTagHandler = tagHandler;//自定义标签器
mReader = parser;//解析器
}
public Spanned convert() { //设置内容处理器
mReader.setContentHandler(this);
try { //开始解析
mReader.parse(new InputSource(new StringReader(mSource)));
} catch (IOException e) {
// We are reading from a string. There should not be IO problems.
throw new RuntimeException(e);
} catch (SAXException e) {
// TagSoup doesn't throw parse exceptions.
throw new RuntimeException(e);
}
//省略
...
...
return mSpannableStringBuilder;
}通过上面代码可以发现,SpannableStringBuilder是用来存放解析html标签中的字符串,类似StringBuilder,但它附带有样式的字符串。重点关注convert里面的setContentHandler方法,该方法接收的是ContentHandler接口,使用过SAX解析的读者应该不陌生,该接口定义了一系列SAX解析事件的方法。
public interface ContentHandler{
//设置文档定位器
public void setDocumentLocator (Locator locator);
//文档开始解析事件
public void startDocument ()
throws SAXException;
//文档结束解析事件
public void endDocument()
throws SAXException;
//解析到命名空间前缀事件
public void startPrefixMapping (String prefix, String uri)
throws SAXException;
//结束命名空间事件
public void endPrefixMapping (String prefix)
throws SAXException;
//解析到标签事件
public void startElement (String uri, String localName,
String qName, Attributes atts)
throws SAXException;
//标签结束事件
public void endElement (String uri, String localName,
String qName)
throws SAXException;
//标签中内容事件
public void characters (char ch[], int start, int length)
throws SAXException;
//可忽略的空格事件
public void ignorableWhitespace (char ch[], int start, int length)
throws SAXException;
//处理指令事件
public void processingInstruction (String target, String data)
throws SAXException;
//忽略标签事件
public void skippedEntity (String name)
throws SAXException;
}对应HtmlToSpannedConverter中的实现。
public void setDocumentLocator(Locator locator) {}
public void startDocument() throws SAXException {}
public void endDocument() throws SAXException {}
public void startPrefixMapping(String prefix, String uri) throws SAXException {}
public void endPrefixMapping(String prefix) throws SAXException {}
public void startElement(String uri, String localName, String qName, Attributes attributes)
throws SAXException {
handleStartTag(localName, attributes);
}
public void endElement(String uri, String localName, String qName) throws SAXException {
handleEndTag(localName);
}
public void characters(char ch[], int start, int length) throws SAXException { //忽略
...
}
public void ignorableWhitespace(char ch[], int start, int length) throws SAXException {}
public void processingInstruction(String target, String data) throws SAXException {}
public void skippedEntity(String name) throws SAXException {}我们发现该类中只实现了startElement,endElement,characters这三个方法,所以只关心标签的类型和标签里的字符。然后调用mReader.parse方法,开始对HTML进行解析。解析的事件流如下: startElement -> characters -> endElement startElemnt里面调用的是handleStartTag方法,endElement则是调用handleEndTag方法。篇幅所限,handleStartTag方法解析可点击“阅读原文”查看。
从handleStartTag方法中我们可以总结出支持的HTML标签列表:
br
p
div
strong
b
em
cite
dfn
i
big
small
font
blockquote
tt
monospace
a
u
sup
sub
h1-h6
img
标签是如何处理的
br标签
这里分析如何处理标签,在handleStartTag方法中可以发现br标签直接被忽略了,在handleEndTag方法中才被真正处理。
private void handleEndTag(String tag) {
...
if (tag.equalsIgnoreCase('br')) {
handleBr(mSpannableStringBuilder);
}
...
}
//代码很简单,直接加换行符
private static void handleBr(SpannableStringBuilder text) {
text.append('
');
}p标签
p标签为段落,其作用是给p标签中的文字前后换行,在handleStartTag和handleEndTag遇到p标签都是调用handleP方法,characters则添加p标签之间的字符串。
private void handleStartTag(String tag, Attributes attributes) {
...
else if (tag.equalsIgnoreCase('p')) {
handleP(mSpannableStringBuilder);
}
...
}private void handleEndTag(String tag) {
...
else if (tag.equalsIgnoreCase('p')) {
handleP(mSpannableStringBuilder);
}
...
}private static void handleP(SpannableStringBuilder text) {
int len = text.length();
if (len >= 1 && text.charAt(len - 1) == '
') {
if (len >= 2 && text.charAt(len - 2) == '
') {
//如果前面两个字符都为换行符,则忽略
return;
}
//否则添加一个换行符
text.append('
');
return;
}
//其他情况添加两个换行符
if (len != 0) {
text.append('
');
}
}strong标签
该标签作用是为加粗字体,在handleStartTag和handleEndTag分别调用start和end方法。
private void handleStartTag(String tag, Attributes attributes) {
...
else if (tag.equalsIgnoreCase('strong')) {
start(mSpannableStringBuilder, new Bold());
}
...
}private static class Bold { }//什么都没有
private void handleEndTag(String tag) {
...
else if (tag.equalsIgnoreCase('strong')) {
end(mSpannableStringBuilder, Bold.class, new StyleSpan(Typeface.BOLD));
}
...
}
private static void start(SpannableStringBuilder text, Object mark) {
int len = text.length();
//mark作为类型标记并没有实际功能,指明开始的位置,
//结束位置延迟到`end`方法中处理,
//Spannable.SPAN_MARK_MARK表示当文本插入偏移时,它们仍然保持在它们的原始偏移量上。从概念上讲,文本是在标记之后添加的。
text.setSpan(mark, len, len, Spannable.SPAN_MARK_MARK);
}
private static void end(SpannableStringBuilder text, Class kind,Object repl) {
//当前字符长度
int len = text.length();
//根据kind获取最后一个set进去的对象
Object obj = getLast(text, kind);
//获取标签起始位置
int where = text.getSpanStart(obj);
//去除标记对象
text.removeSpan(obj);
if (where != len) {
//len则为结束的位置,Spannable.SPAN_EXCLUSIVE_EXCLUSIVE是设置样式文字区间为闭区间
//将真正的样式对象repl设置进去,Bold对应StyleSpan类型,Typeface.BOLD 加粗样式
text.setSpan(repl, where, len, Spannable.SPAN_EXCLUSIVE_EXCLUSIVE);
}
}
private static Object getLast(Spanned text, Class kind) {
/*
* 获取最后一个类型为king,在setSpan传入的对象
* 例如kind类型为Bold.class,则会返回在start中set进去的Bold对象
*/
Object[] objs = text.getSpans(0, text.length(), kind);
if (objs.length == 0) {
return null;
} else {
//如果有期间有多个,则获取最后一个
return objs[objs.length - 1];
}
}经过start和end方法处理后,strong标签中的文本就被加粗,具体的样式类型这里不做详解,后续可以参考Spannable源码解析这篇目前还没人认领文章,其他为字体设置不同的样式过程一致,在handleStartTag根据不同标签类型调用start时方法传入不同对象给mark,并在handleEndTag中不同标签调用end并传入不同样式。
font标签
font标签可以给字符串指定颜色和字体。
private void handleStartTag(String tag, Attributes attributes) {
...
else if (tag.equalsIgnoreCase('font')) {
//attributes带有标签中的属性
//例如<font color='#FFFFFF'>,属性将以key-value的形式存在,{'color':'#FFFFFF'}。
startFont(mSpannableStringBuilder, attributes);
}
...
}
private static void startFont(SpannableStringBuilder text,Attributes attributes) {
String color = attributes.getValue('', 'color');//获取color属性
String face = attributes.getValue('', 'face');//获取face属性
int len = text.length();
//Font同样是一个用来标记属性的对象,没有实际功能
text.setSpan(new Font(color, face), len, len, Spannable.SPAN_MARK_MARK);
}
//保存颜色值和字体类型private static class Font {
public String mColor;
public String mFace;
public Font(String color, String face) {
mColor = color;
mFace = face;
}
}
private void handleEndTag(String tag) {
...
else if (tag.equalsIgnoreCase('font')) {
endFont(mSpannableStringBuilder);
}
...
}
private static void endFont(SpannableStringBuilder text) {
int len = text.length();
Object obj = getLast(text, Font.class);
int where = text.getSpanStart(obj);
text.removeSpan(obj);
if (where != len) {
Font f = (Font) obj;
//前面与strong标签解析过程相似,多了下面处理颜色和字体的逻辑
if (!TextUtils.isEmpty(f.mColor)) {
//如果color属性中以'@'开头,则是获取colorId对应的颜色值
//注意:只能支持android.R的资源
if (f.mColor.startsWith('@')) {
Resources res = Resources.getSystem();
String name = f.mColor.substring(1);
int colorRes = res.getIdentifier(name, 'color', 'android');
if (colorRes != 0) {
//也可以是color selector,则会根据不同状态显示不同颜色
ColorStateList colors = res.getColorStateList(colorRes, null);
//1、通过TextAppearanceSpan设置颜色
text.setSpan(new TextAppearanceSpan(null, 0, 0, colors, null),
where, len,
Spannable.SPAN_EXCLUSIVE_EXCLUSIVE);
}
} else {
//如果为'#'开头则解析颜色值
int c = Color.getHtmlColor(f.mColor);
if (c != -1) {
//2、通过ForegroundColorSpan直接设置字体的rgb值
text.setSpan(new ForegroundColorSpan(c | 0xFF000000),
where, len,
Spannable.SPAN_EXCLUSIVE_EXCLUSIVE);
}
}
}
if (f.mFace != null) {
//如果有face参数则通过TypefaceSpan设置字体
text.setSpan(new TypefaceSpan(f.mFace), where, len,
Spannable.SPAN_EXCLUSIVE_EXCLUSIVE);
}
}
}具体支持哪些字体,在TypefaceSpan的apply方法中会先去解析对应的字体,然后绘制出来,源码如下。
private static void apply(Paint paint, String family) {
...
//解析字体
Typeface tf = Typeface.create(family, oldStyle);
...
}Typeface源码如下:
/**
* 根据字体名称获取字体对象,如果familyName为null,则返回默认字体对象
* 调用getStyle可查看该字体style属性
*
* @param 字体名称,可能为null
* @param style NORMAL(标准), BOLD(粗体), ITALIC(斜体), BOLD_ITALIC(粗斜)
* @return 匹配的字体
*/public static Typeface create(String familyName, int style) {
if (sSystemFontMap != null) {
//字体缓存在sSystemFontMap中
return create(sSystemFontMap.get(familyName), style);
}
return null;
} //init方法中初始化sSystemFontMap
private static void init() {
// 获取字体配置文件目录
//private static File getSystemFontConfigLocation() {
//return new File('/system/etc/');
//}
File systemFontConfigLocation = getSystemFontConfigLocation();
//获取字体配置文件
//static final String FONTS_CONFIG = 'fonts.xml';
File configFilename = new File(systemFontConfigLocation, FONTS_CONFIG);
try { //将字体名称更Typeface对象缓存在map中
//具体解析过程忽略,有兴趣可自行翻阅源码
....
sSystemFontMap = systemFonts;
} catch (RuntimeException e) {
....
}
}img标签
//img标签只有在标签开始时处理
private void handleStartTag(String tag, Attributes attributes) {
...
else if (tag.equalsIgnoreCase('img')) {
startImg(mSpannableStringBuilder, attributes, mImageGetter);
}
...
}//与其他标签处理过程多了Attributes标签属性,Html.ImageGetter 自定义图片获取
private static void startImg(SpannableStringBuilder text,
Attributes attributes, Html.ImageGetter img) {
//获取src属性
String src = attributes.getValue('', 'src');
Drawable d = null; if (img != null) {
//调用自定义的图片获取方式,并传入src属性值
d = img.getDrawable(src);
} if (d == null) {
//如果图片为空,则返回一个小方块
d = Resources.getSystem().
getDrawable(com.android.internal.R.drawable.unknown_image);
d.setBounds(0, 0, d.getIntrinsicWidth(), d.getIntrinsicHeight());
} int len = text.length();
//添加图片占位字符
text.append('uFFFC');
//通过使用ImageSpan设置图片效果
text.setSpan(new ImageSpan(d, src), len, text.length(),
Spannable.SPAN_EXCLUSIVE_EXCLUSIVE);
}自定义标签
private void handleStartTag(String tag, Attributes attributes) {
...
else if (mTagHandler != null) {
//通过自定义标签处理器来扩展自定义标签
mTagHandler.handleTag(true, tag, mSpannableStringBuilder, mReader);
}
...
}
private void handleEndTag(String tag) {
...
else if (mTagHandler != null) {
//闭合标签
mTagHandler.handleTag(false, tag, mSpannableStringBuilder, mReader);
}
...
}
关于自定义标签有个小问题是,handleTag并没有传入Attributes标签属性,所以无法直接获取自定义标签的属性值,下面给出两种方案解决这个问题:
1.通过某一部分标签名作为属性值,例如<custom>标签,我们想加入id的参数,则可将标签名变为<custom-id-123>,然后在handleTag中自行解析。
2.通过反射XMLReader来获取属性值,具体例子可参考stackoverflow:How to get an attribute from an XMLReader
convert方法剩下部分
不要忽略了parse之后还有一部分代码。
//修正段落标记范围
//ParagraphStyle为段落级别样式
Object[] obj = mSpannableStringBuilder.getSpans(0, mSpannableStringBuilder.length(), ParagraphStyle.class);
for (int i = 0; i < obj.length; i++) {
int start = mSpannableStringBuilder.getSpanStart(obj[i]);
int end = mSpannableStringBuilder.getSpanEnd(obj[i]); // 去除末尾两个换行符
if (end - 2 >= 0) {
if (mSpannableStringBuilder.charAt(end - 1) == '
' &&
mSpannableStringBuilder.charAt(end - 2) == '
') {
end--;
}
}
if (end == start) {
//除去没有显示的样式
mSpannableStringBuilder.removeSpan(obj[i]);
} else {
//Spannable.SPAN_PARAGRAPH以换行符为起始点和终点
mSpannableStringBuilder.setSpan(obj[i], start, end, Spannable.SPAN_PARAGRAPH);
}
}
return mSpannableStringBuilder;篇幅所限,完整内容可点击左下角“阅读原文”查看。
这么多优质的国外程序员网站都给你整理好了 别愣着快看啊!
使用Kotlin开发Android项目-Kibo (二)
223 个常用的自定义view和第三方类库
View单位转换的秘密【系统源码分析】
欢迎大家到安卓巴士论坛博文专区发表博文,优秀的文章我们会进行多渠道推荐。详情可见《作为一名优秀的程序猿 你真的够格吗?》
文章为用户上传,仅供非商业浏览。发布者:Lomu,转转请注明出处: https://www.daogebangong.com/articles/detail/Android%20rich%20text%20Html%20source%20code%20detailed%20analysis.html
 支付宝扫一扫
支付宝扫一扫 
评论列表(196条)
测试