在有關深度學習的實際科研或工程中,經常需要在本機上復現別人的程式碼,而由於Python和Pytorch各個版本存在不相容的現象,最讓人頭痛的就是深度學習的環境配置問題,特別是需要用到GPU進行加速時,配置好了這個,卻影響了之前的工程,如何解決這一痛點問題,請閱讀本教學。
相較於網路上面的其他教程,本教程所示方法最大的優點是在執行不同環境配置要求的工程時候,不需要重複安裝/卸載電腦本機的cuda程序,可以大大節約環境配置時間,更重要的是不會因為更改顯示卡配置而影響其他軟體或程序的正常運作。
本文最後透過深度學習入門案例手寫字體辨識(MNIST)的程式驗證本文方法的有效性。

- Anaconda
Anaconda是一個用於科學計算和資料分析的免費開源發行版,包含了許多常用的Python資料科學函式庫和工具,如NumPy、Pandas、Matplotlib、SciPy等。 Anaconda提供了一個套件管理器,讓使用者可以輕鬆安裝、更新和刪除套件。使用Anaconda配置環境相對於直接配置環境有下列優點:
- 方便管理依賴項:Anaconda自帶的套件管理器Conda可以方便安裝和管理Python套件及其依賴項,避免了手動安裝依賴項的繁瑣過程。同時,使用Conda,可以輕鬆建立和刪除虛擬環境,避免了環境污染和版本衝突的問題。
- 包含常用的資料分析和科學計算工具:Anaconda預設安裝了許多資料分析和科學計算函式庫,如NumPy、Pandas、Matplotlib、SciPy等。這些函式庫是資料分析和科學計算中經常使用的工具,使用Anaconda可以避免手動安裝這些函式庫和相依性的繁瑣流程。
- 跨平台支援:Anaconda可以在Windows、Linux和MacOS等多個作業系統上運行,因此可以在不同的開發環境中共享相同的Python程式碼和依賴項,避免了因為不同作業系統導致的相容性問題。
相較之下,直接配置環境需要手動安裝依賴項和環境配置,操作相對繁瑣,同時也容易出現版本衝突和環境污染等問題。因此,使用Anaconda配置環境可以更方便、更快速地完成環境配置,提高了開發效率和程式碼可維護性。
- Pytorch
PyTorch是一個由Facebook開發的基於Python的開源機器學習框架,主要用於建構神經網路和深度學習模型。 PyTorch提供了一個靈活的張量計算庫,可在GPU和CPU上進行高效的數值計算,並支援自動求導和動態計算圖。 PyTorch在深度學習領域中得到了廣泛應用,被用於影像分類、目標偵測、語音辨識、自然語言處理等多個領域。同時,PyTorch也被用於研究領域,許多最新的研究成果都是基於PyTorch實現的。
- Anaconda3的安裝:較為容易,可參考網路上其他教學。
- 基於Anaconda3的環境配置
1、選擇以管理員身分執行Anaconda Prompt
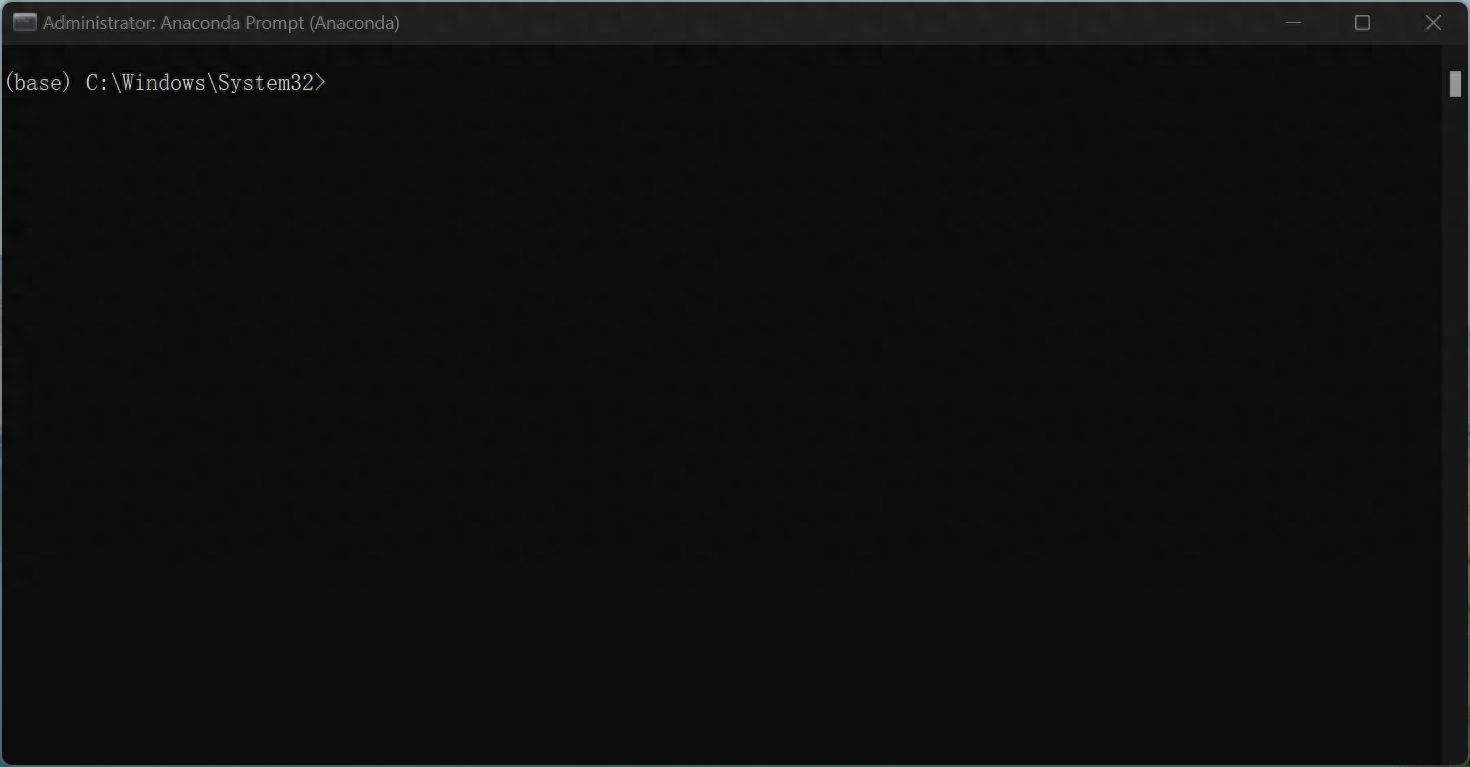
開啟後命令列的最前方為(base),"base"是指預設創建的Python環境,當使用Anaconda創建新的Python環境時,可以選擇在"base"環境的基礎上建立新的環境,或從零開始建立新的環境。新建立的環境將不會包含"base"環境中的預設套件和工具,但是可以透過安裝新的套件和工具來擴充該環境的功能。 寫本文的目的在於讓各類python工程之間不互相影響,因此盡量不要在base環境下做任何更改性的操作!
2、接下來考慮自己要創建什麼樣的環境,本文以創建使用python3.6.2的pytorch為1.7的環境作為範例。 (這裡python的版本和pytorch版本,以及後續cudatoolkit版本需對應好)
輸入 :
conda create --name pytorch17 python==3.6.2這句程式碼的意識是創造一個名字為「pytorch17」的環境,用的是python=3.6.2
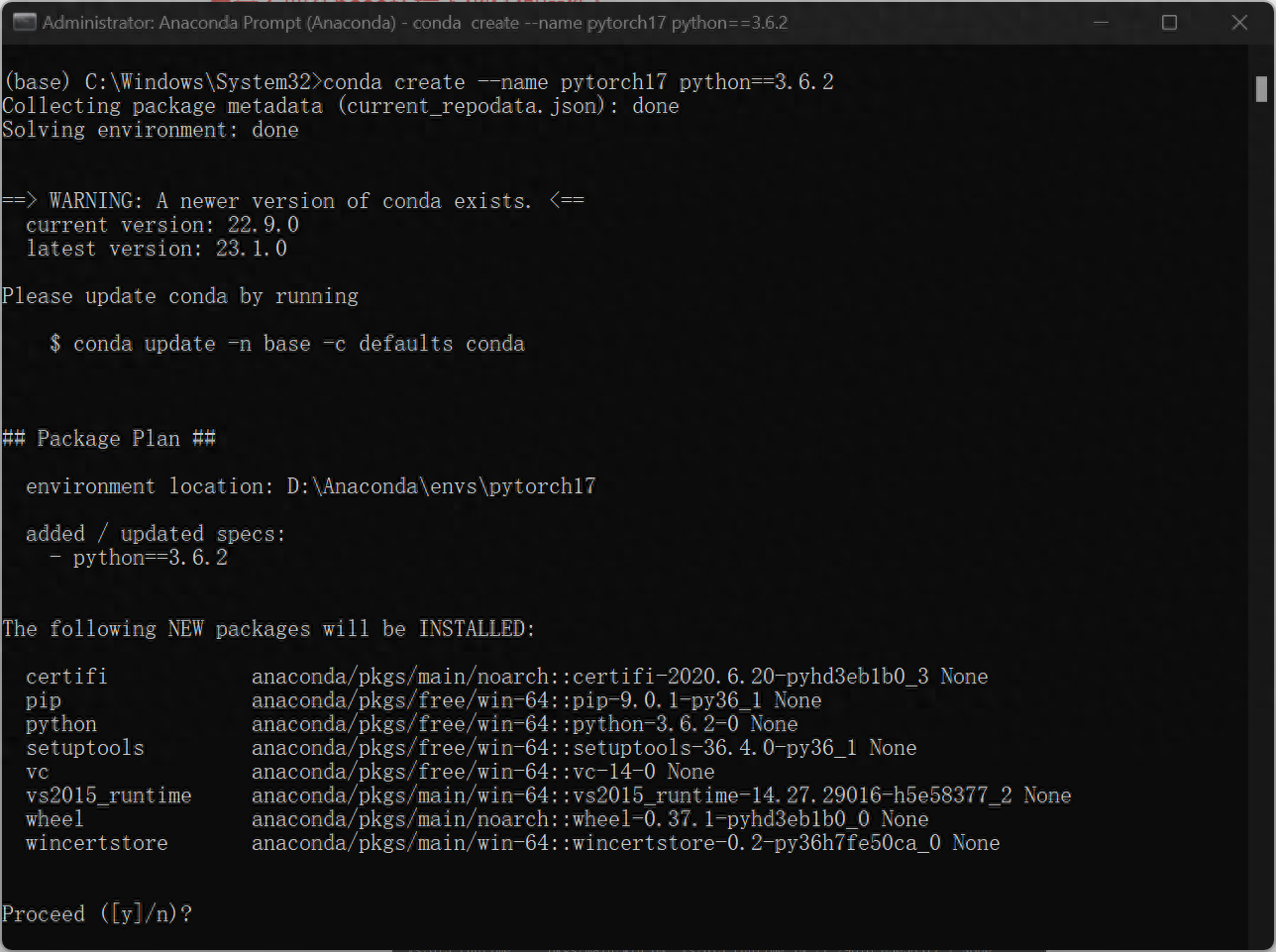
確認安裝,輸入y
然後進行下載安裝
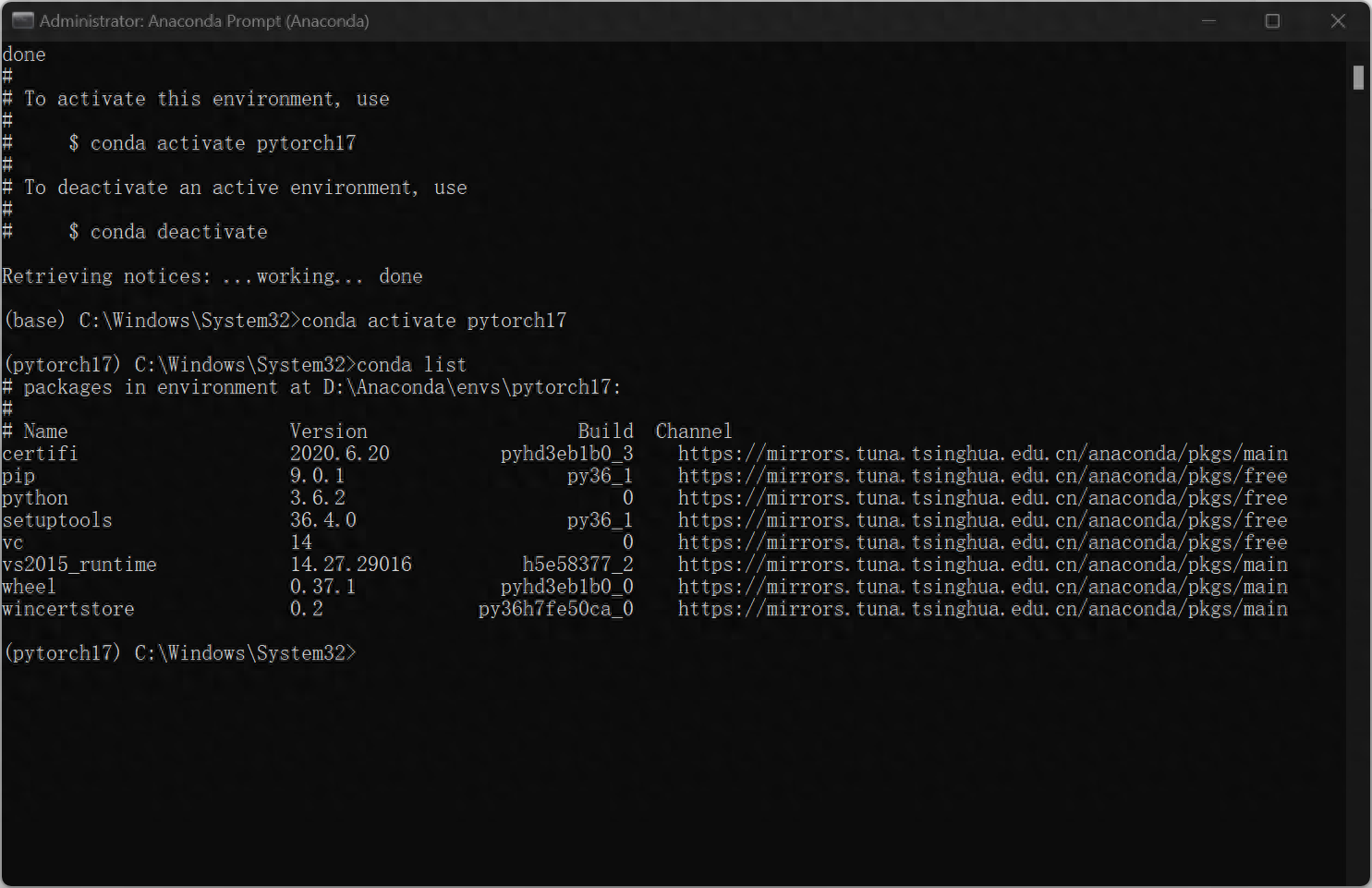
安裝完畢後輸入
conda activate pytorch17即進入剛剛建立的pytorch17環境中,此時發現命令列前面變成(pytorch17),接著鍵入:conda list,展示pytorch所安裝的python包,至此環境已建立完畢。
3、接下來配置Pytorch-GPU,範例中作者想要建立的pytorch版本是1.7.0,cuda版本是11.0
輸入:
conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=11.0 -c pytorch若想安裝不同版本的pytorch和cuda,可查詢網站:https://pytorch.org/get-started/previous-versions/
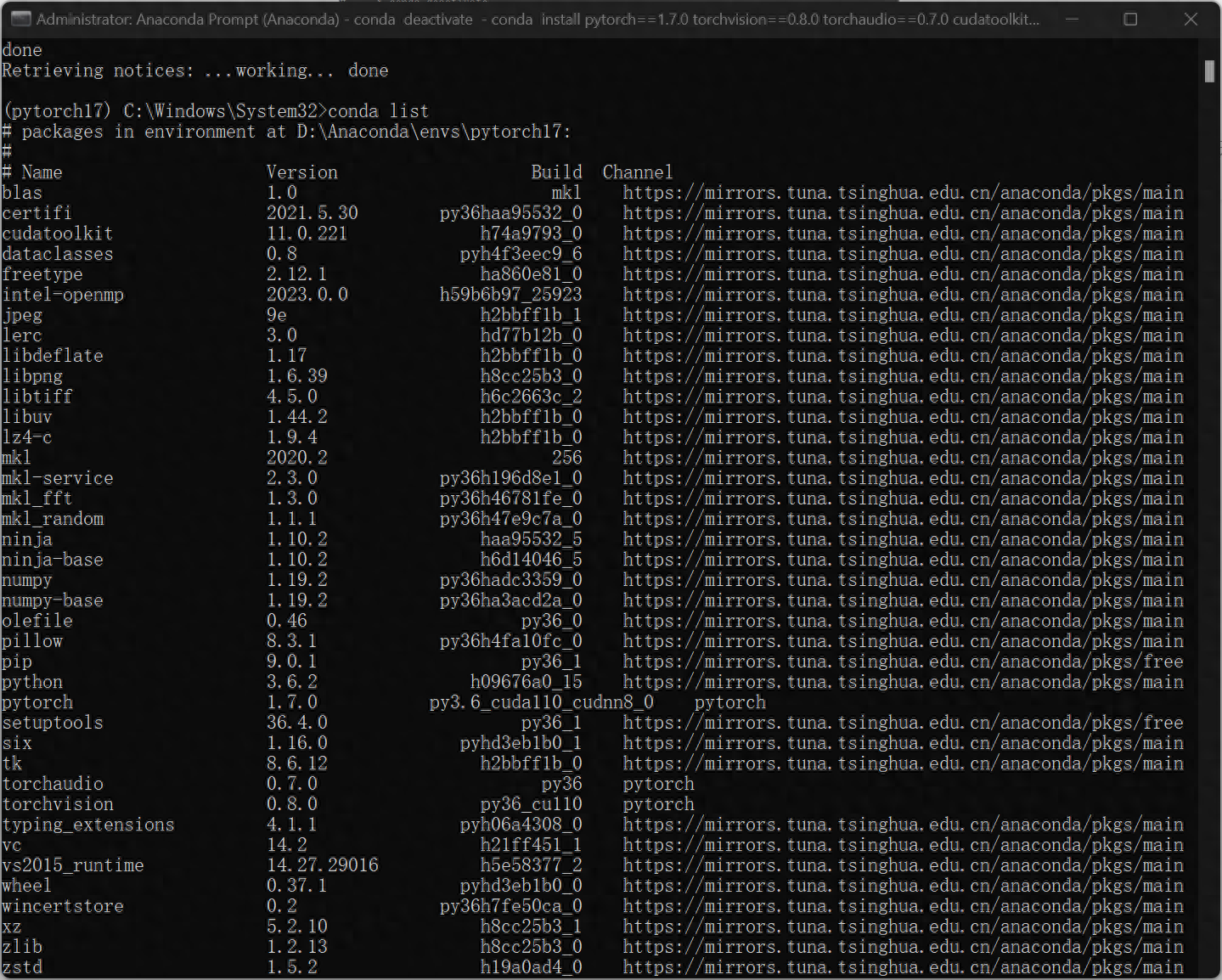
4、驗證是否GPU是否運作
python>>import torch>>torch.cuda.is_available()回傳True即表示GPU正常運作。
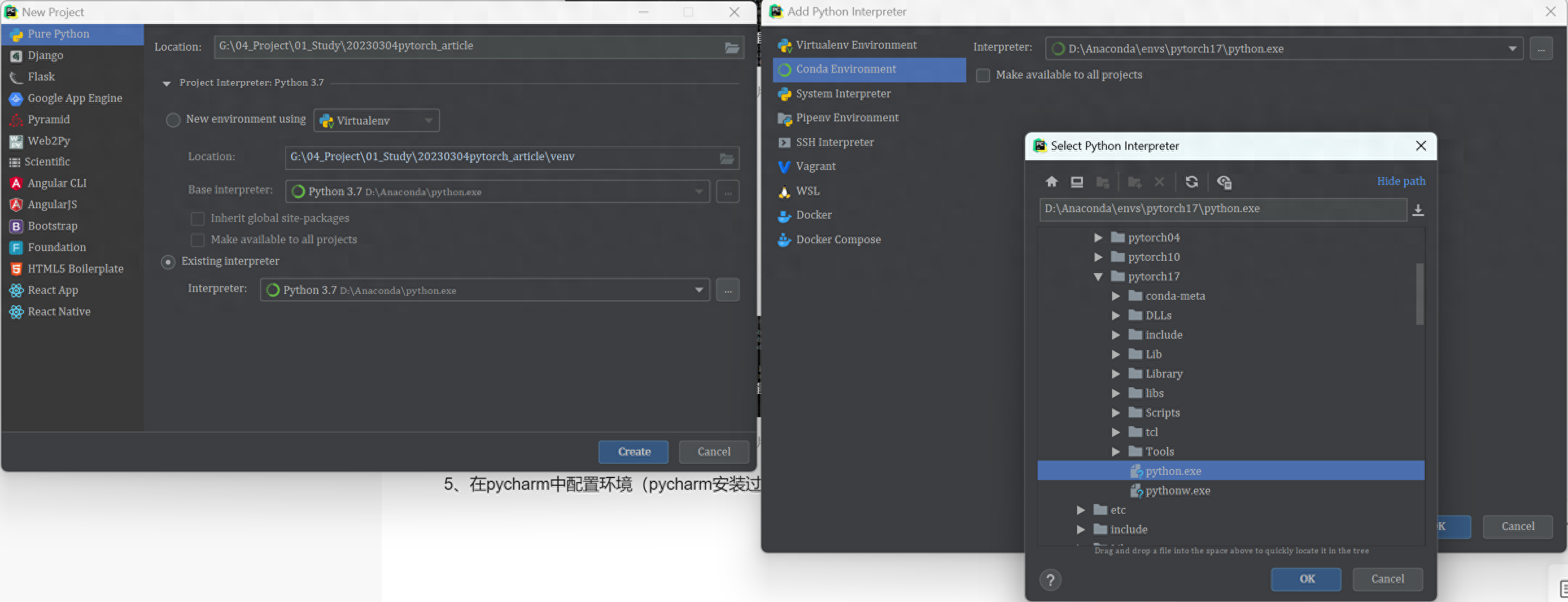
5、在pycharm中配置環境(pycharm安裝過程略)
在新建工程的過程中,選擇existing interpreter,再選擇剛創立好的pytorch17,如圖所示:
至此,可以開始程式設計了。
6、手寫字型辨識驗證環境正確
建立檔案:
複製此程式碼並執行(如需取得全部程式碼請關注公粽號:控我所思VS制之以衡)
import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimfrom torchvision import datasets, transformsBATCH_SIZE = 1024*50 #dev 的資料.DEVICE = 3024*50 #mudaS. torch.cuda.is_available() else "cpu")print(torch.cuda.is_available())EPOCHS = 20 # 訓練資料集的輪次pipeline = transforms.Compose([ transforms.ToTensor(), # 將圖片轉換成tensor transforms.Normalize((0.1307,), (0.3081,)) # 降低模型的複雜度,正則化])from torch.utils.data import DataLoader# 下載資料集train_set = datasets.MNIST("data", train= True, download=True, transform=pipeline)test_set = datasets.MNIST("data", train=False, download=True, transform=pipeline)# 載入資料train_loader = DataLoader(train_set, batch_sizeBATCH _SIZEed==TCH. = DataLoader(test_set, batch_size=BATCH_SIZE, shuffle=True)# 建構網路class Digit(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(1, 10, 5 ) self.conv2 = nn.Conv2d(10, 20, 3) self.fc1 = nn.Linear(20 * 10 * 10, 500) self.fc2 = nn.Linear(500, 10) def forward(self, x) : input_size = x.size(0) x = self.conv1(x) x = F.relu(x) x = F.max_pool2d(x, 2, 2) x = self.conv2(x) x = F.relu (x) x = x.view(input_size, -1) x = self.fc1(x) x = F.relu(x) x = self.fc2(x) output = F.log_softmax(x, dim=1) # 計算分類後,每個數字的機率值return outputmodel = Digit().to(DEVICE)optimizer = optim.Adam(model.parameters())def train_model(model, device, train_loader, optimizer, epoch): # 模型訓練model.train() for batch_index, (data, target) in enumerate(train_loader): # 部署到device上去data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model (data) loss = F.cross_entropy(output, target) # 反向傳播loss.backward() optimizer.step() if batch_index % 3000 == 0: print("Train Epoch : {} \t Loss : {:. 6f}".format(epoch, loss.item()))def test_model(model, device, test_loader): model.eval() correct = 0.0 test_loss = 0.0 with torch.no_grad(): for test, target in test_loader data, target = data.to(device), target.to(device) output = model(data) test_loss += F.cross_entropy(output, target).item() pred = output.max(1, keepdim=True) [1] correct += pred.eq(target.view_as(pred)).sum().item() test_loss /= len(test_loader.dataset) print("Test Average loss : {:.4f},Accuracy : { :.3f}\n".format(test_loss,100.0 * correct / len(test_loader.dataset)))for epoch in range(1, EPOCHS + 1): train_model(model, DEVICE, train_loader, optimizer, 4och) test. model, DEVICE, test_loader)程式碼開始運行,下載MNIST手寫字型識別的資料集。
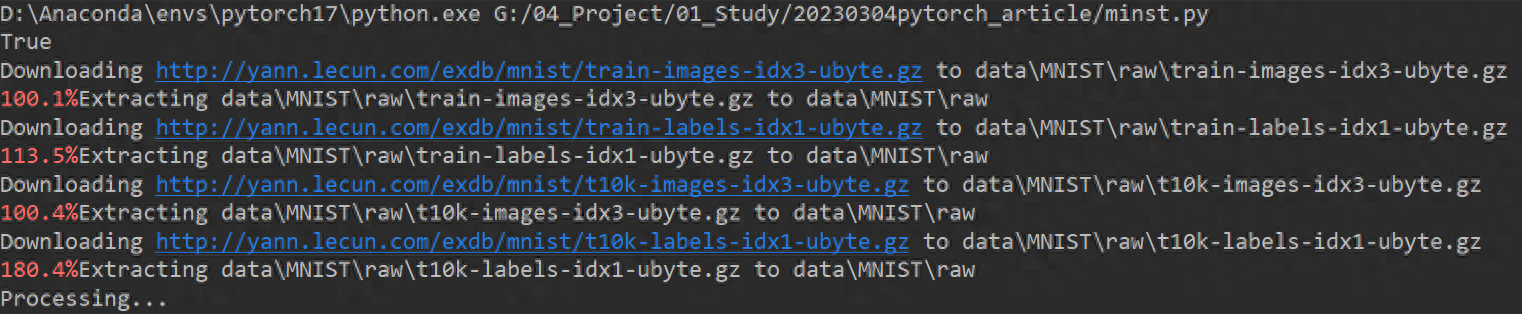
訓練開始:

此時用win+R,輸入cmd,再輸入nvidia-smi檢查顯示卡狀況,顯示卡正在工作中
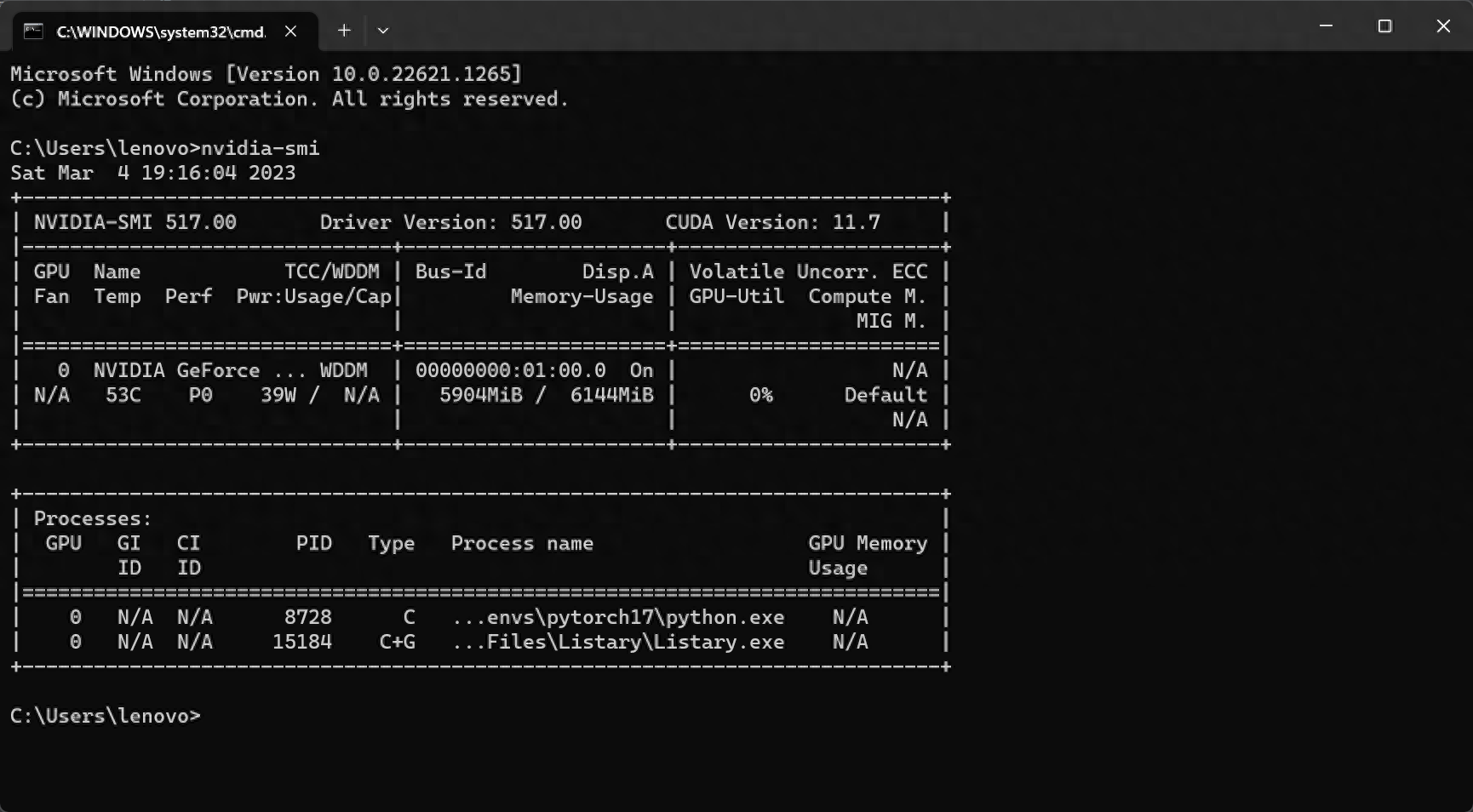
此時已經全部完成,可以專注編寫程式碼了。
7.若想刪除設定的環境,重新開啟Anaconda Prompt 輸入以下程式碼
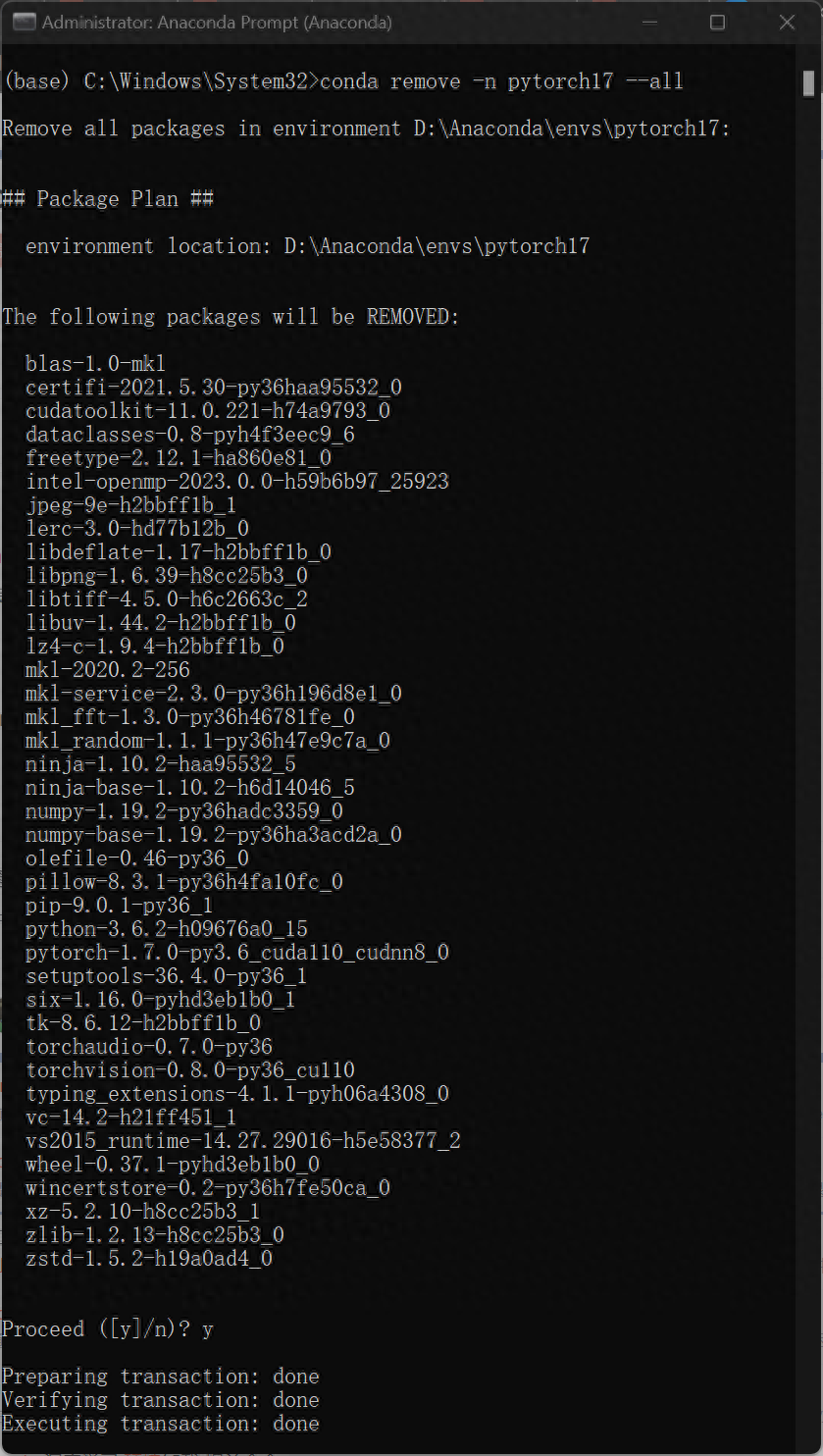
本篇教學所示方法最大的優點就是在執行不同環境配置要求的工程時候,不需要重複安裝/卸載電腦本機的cuda文件,可以大大節省環境配置時間,更重要的是不會因為更改顯示卡配置而影響其他軟體或程式的正常運作。
製作不易,喜歡請按讚、留言、收藏、追蹤!
文章為用戶上傳,僅供非商業瀏覽。發布者:Lomu,轉轉請註明出處: https://www.daogebangong.com/zh-Hant/articles/detail/pei-zhi-shen-du-xue-xi-PytorchGPU-Cuda-huan-jing-tu-wen-jiao-cheng-ji-shou-xie-zi-ti-shi-bie-yan-zheng.html
 支付宝扫一扫
支付宝扫一扫 
评论列表(196条)
测试