
其實當你了解了這兩種編碼方式後,就會知道GBK是中國標準,UTF8是網路傳輸標準,Unicode是全球標準。
我們先介紹下GBK:(GBK的發展史)
那我們不得不提的是區位碼:
其中前兩位為“區”,後兩位為“位”,中文漢字的編號區號是從16開始的,位元號從1開始。前面的區號有一些符號、數字、字母、注音符號(台)、製表符、日文等等。簡單來說就是0~1599表示的是除漢字之外的字號。 1600~9999其中部分代表漢字編號,當然當時的漢字數量應該沒有佔用完所有的編號。
接下來發展到GB2312:
是基於區位碼的,用雙字節編碼表示中文和中文符號。一般編碼方式是:0xA0+區號,0xA0+位號。如下表中的 “安”,區位號是1618(十進位),那麼“安”字的GB2312編碼就是 0xA0+16 0xA0+18 也就是 0xB0 0xB2 。根據區位碼表,GB2312的漢字編碼範圍是0xB0A1~0xF7FE
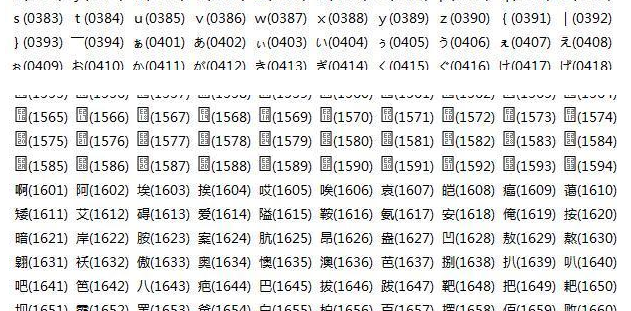
以ASCII編碼,也就是說現代的GBK編碼是相容ASCII編碼的。例如一個數字2,對應的二進位是0x32,而不是 0xA3 0xB2。那麼問題來了,0xA3 0xB2 又對應到什麼呢?還是2。注意看了,這裡的2跟2是不是有點不太一樣? !確實是不一樣的。這裡的雙位元組2是全角的二,ASCII的2是半角的二,一般輸入法裡的切換全角半角就是這裡不同。

那麼其實GBK就是GB2312的補充,當然以後GB18030是對GBK的補充
在同一個編碼檔案裡,要怎麼區分ASCII和中文編碼呢?從ASCII表我們知道標準ASCII只有128個字符,0~127即0x00~0x7F(0111 1111)。所以區分的方法就是,高位元組的最高位元為0則為ASCII,為1則為中文。
現在我們國家的GBK介紹完了,看下來是不是有點豁然開朗的感覺!其實就是一種一一對應漢字的編號方式,嘿嘿!
那我們接下來來看看全球是怎麼編碼的呢?其實也是類似,只是這是不只漢字,有全世界各國的字符了。
現行的Unicode編碼標準裡,絕大多數程式語言只支援雙字節,所以Unicode也就是雙字節的標準表示全球所有的字元(可以包含65536中字元),
為英文字元也全部使用雙字節,儲存成本和流量會大幅增加,所以Unicode編碼大多數情況並沒有被原始地使用,而是被轉換編碼成UTF8,這才出現了UTF8.< /strong>
而Unicode與UTF8之間的轉換是透過下面這個表格進行的:
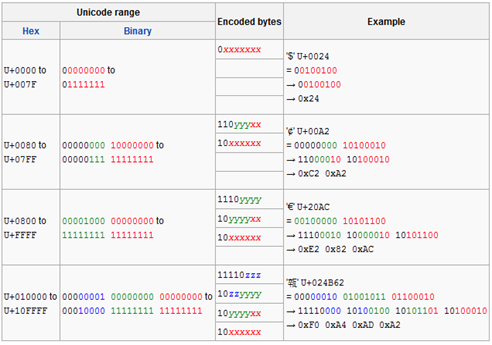
現在還有最後一個問題就是BOM,何為BOM?
所謂BOM頭(Byte Order Mark)就是文字檔中開始的幾個不表示任何字元的字節,用二進位編輯器(如bz.exe)就能看到了。
UTF8的BOM頭為 0xEF 0xBB 0xBF
Unicode大端模式為 0xFE 0xFF
Unicode小端模式為 0xFF 0xFE
如何區分一個文字是無BOM的UTF8還是GBK?
答案是,只能以大量的編碼分析來區分。目前辨識準確率很高的有:Notepad++等一些常用的IDE,PHP的mb_系列函數,python的chardet函式庫及其它語言衍生版如jchardet,jschardet等

文章為用戶上傳,僅供非商業瀏覽。發布者:Lomu,轉轉請註明出處: https://www.daogebangong.com/zh-Hant/articles/detail/che-di-gao-dong-kun-rao-cheng-xu-yuan-duo-nian-de-GBK-he-UTF8.html
 支付宝扫一扫
支付宝扫一扫 
评论列表(196条)
测试