
來源:機器之心
本文< /span>約2500字,建議閱讀8分鐘
甲方:「我想讓這隻小狗坐下。」AI:安排!

動動嘴皮子就能把圖改好是甲方和乙方的共同願望,但通常只有乙方才知道其中的酸楚。如今,AI 卻向這個高難度問題發起了挑戰。
在一篇10 月17 日上傳到arXiv 的論文中,來自谷歌研究院、以色列理工學院、以色列魏茨曼科學研究所的研究者介紹了一種基於擴散模型的真實圖像編輯方法——Imagic,只用文字就能實現真實照片的PS,比如讓一個人豎起大拇指、讓兩隻鸚鵡親吻:

「求大神幫忙P 一個點贊手勢。」擴散模型:沒問題,包在我身上。
從論文中的圖像可以看出,修改後的圖像依然非常自然,對需要修改的內容之外的信息也沒有明顯的破壞。類似的研究還有谷歌研究院和以色列特拉維夫大學之前合作完成的 Prompt-to-Prompt(Imagic 論文中的參考文獻 [16]):
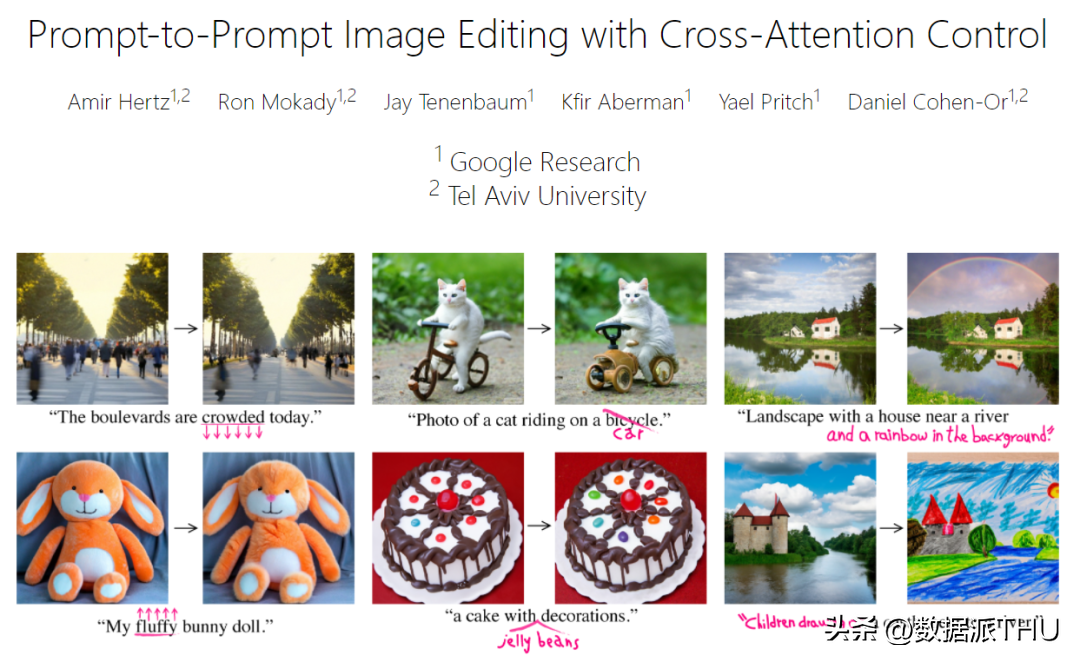
項目鏈接(含論文、代碼):https://prompt-to-prompt.github.io/
因此,有人感慨說,「這個領域變化快到有點誇張了,」以後甲方真的動動嘴就可以想怎麼改就怎麼改了。
Imagic 論文概覽
論文鏈接:https://arxiv.org/pdf/2210.09276.pdf
將大幅度的語義編輯應用於真實照片一直是圖像處理中一個有趣的任務。近年來,由於基於深度學習的系統取得了長足的進步,該任務已經引起了研究社區相當大的興趣。
用簡單的自然語言文本prompt 來描述我們想要的編輯(比如讓一隻狗坐下)與人類之間的交流方式高度一致。因此,研究者們開發了很多基於文本的圖像編輯方法,而且這些方法效果也都不錯。
然而,目前的主流方法都或多或少地存在一些問題,比如:
1. 僅限於一組特定的編輯,如在圖像上作畫、添加對像或遷移風格[6, 28];
2. 只能對特定領域的圖像或合成的圖像進行操作[16 , 36];
3. 除了輸入圖像外,它們還需要輔助輸入,例如指示所需編輯位置的圖像mask、同一主題的多個圖像或描述原始圖像的文本[6, 13, 40, 44]。
本文提出了一種語義圖像編輯方法「Imagic」以緩解上述問題。只需給定一個待編輯的輸入圖像和一個描述目標編輯的單一文本 prompt,該方法就可以對真實的高分辨率圖像進行複雜的非剛性編輯。所產生的圖像輸出能夠與目標文本很好地對齊,同時保留了原始圖像的整體背景、結構和組成。
如圖1 所示,Imagic 可以讓兩隻鸚鵡接吻或讓一個人豎起大拇指。它提供的基於文本的語義編輯首次將如此復雜的操作應用於單個真實的高分辨率圖像,包括編輯多個對象。除了這些複雜的變化之外,Imagic 還可以進行各種各樣的編輯,包括風格變化、顏色變化和對象添加。
為了實現這一壯舉,研究者利用了最近成功的文本到圖像的擴散模型。擴散模型是強大的生成模型,能夠進行高質量的圖像合成。當以自然語言文本 prompt 為條件時,它能夠生成與要求的文本相一致的圖像。在這項工作中,研究者將它們用於編輯真實的圖像而不是合成新的圖像。
如圖3 所示,Imagic 完成上述任務只需要三步走:首先優化一個文本嵌入,使其產生與輸入圖像相似的圖像。然後,對預訓練的生成擴散模型進行微調,以優化嵌入為條件,更好地重建輸入圖像。最後,在目標文本嵌入和優化後的嵌入之間進行線性插值,從而得到一個結合了輸入圖像和目標文本的表徵。然後,這個表徵被傳遞給帶有微調模型的生成擴散過程,輸出最終編輯的圖像。
為了證明Imagic 的實力,研究者進行了幾個實驗,將該方法應用於不同領域的眾多圖像,並在所有的實驗中都產生了令人印象深刻的結果。 Imagic 輸出的高質量圖像與輸入的圖像高度相似,並與所要求的目標文本保持一致。這些結果展示了 Imagic 的通用性、多功能性和質量。研究者還進行了一項消融研究,強調了本文所提出的方法中每個組件的效果。與最近的一系列方法相比,Imagic 表現出明顯更好的編輯質量和對原始圖像的忠實度,特別是在承擔高度複雜的非剛性編輯任務時。
方法細節
給定一個輸入圖像x 和一個目標文本,本文旨在以滿足給定文本的方式編輯圖像,同時還能保留圖像x 的大量細節。為了實現這一目標,本文利用擴散模型的文本嵌入層來執行語義操作,這種方式有點類似於基於 GAN 的方法。研究人員從尋找有意義的表示開始,然後經過生成過程,生成與輸入圖像相似的圖像。之後再對生成模型進行優化,以更好地重建輸入圖像,最後一步是對潛在表示進行處理,得到編輯結果。
如上圖3 所示,本文的方法由三個階段構成:(1 )優化文本嵌入以在目標文本嵌入附近找到與給定圖像最匹配的文本嵌入;(2)微調擴散模型以更好地匹配給定圖像;(3)在優化後的嵌入和目標文本嵌入之間進行線性插值,以找到一個既能達到圖像保真度又能達到目標文本對齊的點。
更具體的細節如下:
文本嵌入優化
首先目標文本被輸入到文本編碼器,該編碼器輸出相應的文本嵌入,其中T 是給定目標文本的token 數,d 是token 嵌入維數。然後,研究者對生成擴散模型 f_θ的參數進行凍結,並利用去噪擴散目標(denoising diffusion objective)優化目標文本嵌入 e_tgt
其中,x 是輸入圖像,是x 的一個噪聲版本,θ為預訓練擴散模型權值。這樣使得文本嵌入盡可能地匹配輸入圖像。此過程運行步驟相對較少,從而保持接近最初的目標文本嵌入,獲得優化嵌入 e_opt。
模型微調
這裡要注意的是,此處所獲得的優化嵌入e_opt 在通過生成擴散過程時,不一定會完全和輸入圖像x 相似,因為它們只運行了少量的優化步驟(參見圖5 中的左上圖)。因此,在第二個階段,作者通過使用公式 (2) 中提供的相同損失函數優化模型參數 θ 來縮小這一差距,同時凍結優化嵌入。
文本嵌入插值
Imagic 的第三個階段是在e_tgt 和e_opt 之間進行簡單的線性插值。對於給定的超參數,得到然後,作者使用微調模型,以 為條件,應用基礎生成擴散過程。這會產生一個低分辨率的編輯圖像,然後使用微調輔助模型對目標文本進行超分辨率處理。這個生成過程輸出最終的高分辨率編輯圖像。
實驗結果
為了測試效果,研究者將該方法應用於來自不同領域的大量真實圖片,用簡單的文字prompt 來描述不同的編輯類別,如:風格、外觀、顏色、姿勢和構圖。他們從 Unsplash 和 Pixabay 收集了高分辨率的免費使用的圖片,經過優化,用 5 個隨機種子生成每個編輯,並選擇最佳結果。 Imagic 展示了令人印象深刻的結果,它能夠在任何一般的輸入圖像和文本上應用各種編輯類別,如圖 1 和圖 7 中所示。
圖2 中是對同一張圖片進行了不同的文字prompt 實驗,顯示了Imagic 的多功能性。
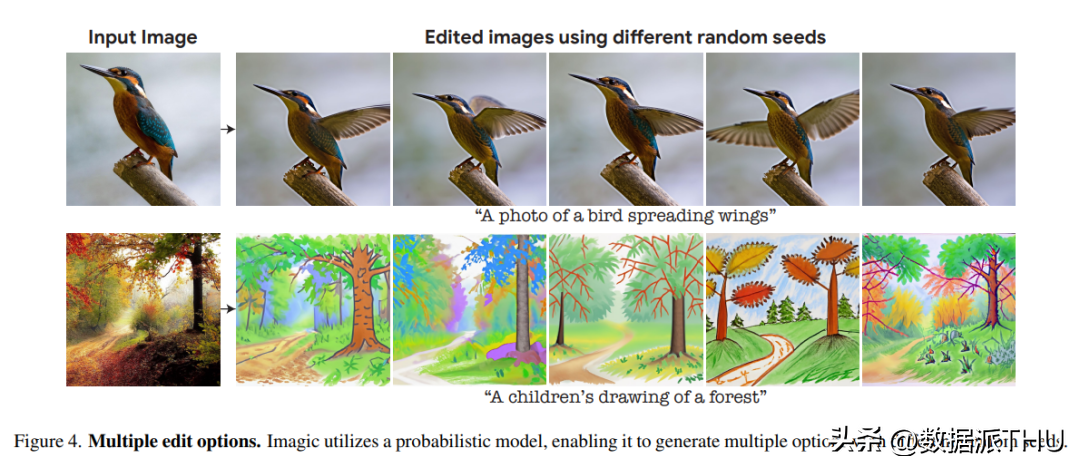
由於研究者利用的底層生成擴散模型是基於概率的,該方法可以對單一的圖像- 文本對生成不同的結果。圖 4 展示了使用不同的隨機種子進行編輯的多個選項(對每個種子的η稍作調整)。這種隨機性允許用戶在這些不同的選項中進行選擇,因為自然語言的文本 prompt 一般都是模糊和不精確的。
研究將Imagic 與目前領先的通用方法進行了比較,這些方法對單一輸入的真實世界圖像進行操作,並根據文本prompt 對其進行編輯。圖 6 展示了 Text2LIVE[7] 和 SDEdit[32] 等不同方法的編輯結果。
可以看出,本文的方法對輸入圖像保持了高保真度,同時恰當地進行了所需的編輯。當被賦予複雜的非剛性編輯任務時,比如「讓狗坐下」,本文方法明顯優於以前的技術。 Imagic 是第一個在單一真實世界圖像上應用這種複雜的基於文本的編輯的 demo。

文章為用戶上傳,僅供非商業瀏覽。發布者:Lomu,轉轉請註明出處: https://www.daogebangong.com/zh-Hant/articles/detail/Unstoppable%20Diffusion%20model%20can%20PS%20photo%20with%20only%20text.html
 支付宝扫一扫
支付宝扫一扫 
评论列表(196条)
测试