
< strong>目標人群:有一定的實證類論文的閱讀基礎,並大對其結構框架,各部分的作用有基本了解。
寫文目的:這篇文章不是實證類論文指導教程,只是為中途你我可能遇到的困難提個醒,以及致敬那些年脫的頭髮。
一、確定研究問題
(一)閱讀文獻
首先你得先有個大方向,可以是你自己感興趣的,也可以是在導師的引導下,但最好是兩者結合,不然看那麼多乾貨,我選擇原地爆炸。一般是確定個核心詞,然後在知網上下載相關文獻。剛開始看文獻,看的特別慢,而且,你幾乎看不懂他說的是什麼意思,沒關係,大家都這樣。不過前幾篇,你最好按著順序看下來,從頭看到尾,理解他的作用機制,這個變量是如何影響另一個變量的,模型一定要重點看,這是你要學習借鑒的地方,包括變量的量化以及數據的來源,不管你想的有多美,找不到數據,還是沒用。看第一遍的時候,可以在文獻中做適當的標記,還可以寫寫感想。但是,看完整篇之後一定要把認為最關鍵的另外摘錄下來!你可以快速瀏覽全篇,重點看標記的地方,摘錄下來!錄下來!下來!請記住我愛的忠告,不然,你會忘得(蜜汁微笑).....我摘錄的內容(僅供參考):題目與作者信息(參考文獻格式)、作用機制、假設、模型、變量量化、數據來源。建議最好摘錄20篇以上,然後對看過的文獻進行適當的歸類與總結,你會慢慢發現這些文獻的相通處。記得讀文獻時適當回顧之前讀過的文獻,你可能會在看某篇時產生靈感,記得一定要寫下來,不然你會忘得......
(二)確定基本模型
關鍵是要確定主要解釋變量以及被解釋變量。做好上述工作之後,你需要重讀自己摘錄的論文信息,然後可以適當組合創新,選擇核心變量,然後再進一步搜索相關的文獻,不斷進行補充與優化。在我看來,問題的確定與基本模型的確定幾乎是一致的。
不同文獻對同一變量可能採取不同的量化方式。確定好主要變量之後,你可以在這些文獻中,選擇最適合自己論文的量化方法,還可以為之後的穩健性檢驗做準備。
二、下載數據
接下來就是找數據了你得知道你每個變量對應的數據,然後去數據庫裡找。我論文研究的問題是與企業相關的,所以可以利用上市公司的相關信息。手頭有的資源是Wind金融數據庫(萬德)和CSMAR數據庫(國泰安),如下對這兩個數據庫就企業類數據談談看法。因為之後數據處理用的是stata軟件,對導入數據有一定的要求,所以還要考慮到之後數據整理的方便性。萬德數據庫只能在特定電腦使用,從萬德上下載數據,一個數據表可以同時下載一個公司的各種信息,但是只可以下載一個時間截點的信息,就是截面數據的樣式,你的面板數據跨越幾個時間點你就需要下載幾個數據表,然後在對下載的數據表進行合併(不停的粘貼複製)。國泰安是移動網頁型,只要有網址,賬號就可以隨時隨地使用,從上面可以直接下載面板數據樣式,但是企業的不同信息存在可能存在於不同的數據表,也就是說,下載完數據後,你也需要合併匹配,並且難度更大,因為不同數據表的樣本數可能不是完全相同的。如果是截面數據,或則時間期數不多的面板數據,建議使用萬德。如果面板數據的跨時間期數較多,建議運用國泰安。前提是你有的選擇。
我的是季度數據,而且跨了幾個年份,所以選擇國泰安(我能說我這個顏狗在看到國泰安的界面時瞬間就被圈粉了嘛)!但是後期數據整理時,那個不同數據表之間的匹配還是折磨死我了,所以我沒思考出,到底是不是萬德更勝一籌,但是,對他的界面實在無愛,原諒我的不理性。
友情提示:下載數據時,不要擔心自己下載的數據信息會不會太多,時間跨度會不會太大。我因為缺少部分信息,在整理報表時不知道返工了多少回,簡直淚目。整理到一半,發現不對勁,又重新回頭下載,反反复复.......特別是關於數據統計方面的信息一定要下載清楚,比如股票代碼,報表截止日期,報表類型等。
Stata導入數據的格式
Excel處理時,第一行為變量名,不同列指代樣本的不同信息。第一列為股票代碼,第二列為年份,第三列為季度,然後依次可以往後輸入其他信息比如企業淨利潤率等。不同企業不同時間點的信息,在每一行錄入。當然,行與行之間順序亂的stata也是可以識別的。建議變量名使用英文,中文不識別。
三、數據處理
從國泰安下載下來的數據有可能分屬於不同的報表類型,我第一次沒有下載報表類型這一信息,然後有些變量在同一時間點有兩個不同的數據,簡直亂了套,後來才發現是報表類型那出了問題。報表類型分為A、B兩種。 A代表母公司報表,B代表總公司報表,下載的數據這二者是混在一起的,所以我們一般要對此先進行分類,一般採取母公司報表數據進行問題研究。
(二)數據刪除
1.刪除金融類企業的數據:金融類槓桿率大,各指標情況同其他企業差距很大,所以研究企業類問題時一般默認刪除。
2.刪除空白數據:如果該企業此月份的某一數據缺失,那整行數據都需要進行刪除
3.刪除不合理數據:你需要對各指標的合理區間進行判斷,也許該指標的數據不可能出現負值,也許不可能大於一,你需要刪除合理區間意外的數據
4.刪除亂碼:有些數據是通過數據間的運算得到,所以有可能得到亂碼,也需要篩選出來一併刪除
刪除數據時可以巧用Excel中的篩選功能。這是就要佩服2007版本的office,可以之間篩選出某一數據進行局部刪除,而WPS就不能。
(三)數據整合
這時候需要把分散在不同Excel表格中的數據整合到一個表中,空白數據的刪除一定要在此項工作之前,因為,當你運用vlookup等函數將表格匹配到一起時,空白處還自動填充成0。在運用Excel進行數據處理時。一定記得問度娘,可以是很小白的問題,你會發現原來Excel還可以這樣操作!不要傻傻地自己手工操作。 (我一開始就是這樣,心痛到不能呼吸,度娘比你想像的強大,Excel的騷操作也不是你我可以膜拜的)
(四)數據變換
Stata只會識別數值型數據,只認英文和阿拉伯數字,所以不合格的當你導入stata時通通標紅。我遇見的幾種情況:
股票代碼000001,000002——NO;日期2018/01/01/ 、20180101——NO;78%——NO;文本類數據— —更不可以
至於具體某種情況如何變換成標準樣式,請問度娘,千萬別直接手動變換啊!我用過vlookup,中間還經常匹配不起來,特別是運用文字信息時,你需要比對進行匹配的ID是否一樣,比如廣東和廣東省就不可以;對日期的處理運用過Excel中“分列”,left等。
四、運用stata進行數據處理
同之前說的,我研究問題用的是各企業的面板數據,所以下列只是我在用stata時處理面板數據的常用命令的介紹。再說一次,這也不是stata教程,stata的基礎操作還需要你們自己了解,包括數據如何導入,軟件的安裝等。
(一)命令
Clear............................... .................................................. ................................清除數據
generate quarterly=yq(year,
quarter).............................. ..................................定義時間(我使用的是季度數據所以定義為quarterly,如果是月度則變換為monthly)
xtset x1 quarterly............................. .............................將數據定義為“面板”形式,x1是類似於截面數據的編號,好比每個人都有不同的ID,不同上市公司也對應不同的股票代碼
gen
x1_=l.x1........................... .................................................. ....................滯後一期變量溫馨提示:l.後面直接跟上變量名,不可以存在空格
sum x1 x2 x3 x4
................................ .................................................. .............描述性統計包括樣本數、最值、均值和方差等樣本信息,此結果的導出需要直接進行複制粘貼(後續會詳細介紹)
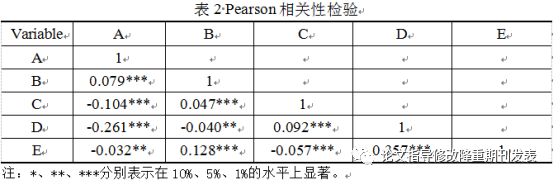
pwcorr_a x1 x2 x3 x4, star1(0.01) star5(0.05) star10(0.1).............. ..................相關性分析star(.01)括號內表示顯著性水平,結果導出的處理方式同描述性統計
xtreg y x1 x2 x3 x4, fe........................ .................................................. ..固定效應回歸命令y是被解釋變量,x是解釋變量fe表示固定效應,使用固定效應時,回歸結果中那些不隨時間變化的變量不會出現係數,只會出現顯著性水平,比如一個人的性別(微笑),企業性質,所在地等
xtreg y x1 x2 x3 x4,
re............................... ..............................................隨機效應回歸命令使用隨機效應時,回歸結果中每個變量都會有係數。恕我才疏學淺,現在還不是很知道如何解釋不同效應的意思
esttab using y8.rtf ,star(* 0.1 ** 0.05 *** 0.01).............. ............................導出回歸結果y8是你要給導出文件的命名,此命令只可以導出回歸結果,但導出不了描述性統計以及相關性分析的結果
如果發現命令輸入一直沒有結果導出,你可以檢查一下命令的各個空格是否正確以及大小寫,stata好像只認英文小寫。
(二)麻煩
如果你發現自己第一次作出來的數據不顯著(我第一次跑數據的P值0.9,想死的心都有,但還是要保持微笑),不要憂傷不要心急!因為明天的你會更慘......收回毒雞湯,我給大家推薦幾種鎮定劑(至於這些方法是否科學,我不好評價,只知道這些方法挺好用的)。
縮尾處理
ssc install
winsor2............................... .................................................. ..安裝縮尾處理(當初百度時,我還傻傻地以為是真要下載什麼安裝包,還研究了好一會,然後我絕望的發現,當你輸入這條命令的時候就叫安裝. .....)
winsor2 x1 x2 x3 x4, replace cut(1 99)
winsor2 x1 x2 x3 x4,replace cut(1 99) trim
縮尾處理的輸入後,需要再次輸入回歸命令xtreg y x1 x2 x3 x4, fe
2.分組處理
可以根據某種標準對數據進行分組,比如按企業性質,可以分為國有企業,民營,外資等
3.刪減數據
這不是指你可以隨意刪減樣本數據,而是對你要研究的區間進行選擇。如果你的樣本容量足夠大,你可以調整所要研究的數據的年份,比如,將2012-2018變為2015-2018;也可以選擇分組中的某一特定類別來研究,但隨之你的理論都得進行相應的解釋;你也可以改變時間頻率,把季度改成月度或則年度。
具體命令的意思以及為什麼要這樣處理,請大家自行了斷(劃掉劃掉,自行了解),我只是為跑數據時不知所措的我們稍微引一下路,少走一些彎路,不然忙活半天到頭來又得重新開始。還是那句話,建議大家有什麼問題可以多問問度娘或查閱相關書籍,求助大神也可以,不要悶頭直乾或放棄。
至於為什麼不再寫的具體些,因為...................... ...........................................懶
五、論文排版
我怕是中了排版的毒,現在幹什麼都要額外花些時間去排版,宋體、小四、行間距固定值22磅,首行縮進兩格(微笑,我也控制不住我自己啊)!每個學校,期刊對論文格式要求都不同,所以也沒有一個統一的標準。但為各位提個醒,先調整頁面佈局的頁邊距,不然你好不容易調好的表格又要跨頁了!建議大家先詳細閱讀論文的排版要求,別看一個調整一個,也不建議用格式刷,不見得有多快,而且你看過之後孰能生巧,哪裡有問題,自己也能看出來。修改格式時建議大家調整出視圖中的格式標記,這樣空格,回車等符號都可以在文檔中顯示出來。
(一)參考文獻
樣本:
[1] 李後健, 張宗盛. 地方官員任期、腐敗與企業研發投入[J]. 科學研究, 2014, 32(05):744- 757.
說明:
1.除文字部分其他都用英文格式;
2.各標點符號後要有空格;
3.除了[1],其他[2][3]都用回車生成
4.[1]-[9]設置為首行縮進1.5磅;[10]之後設置為2,目的是為了對齊
5.如果是使用知網導出,記得刪去最後的導出時間等多餘信息
(二)表格
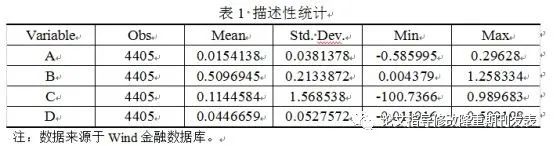
1.描述性統計
導出:選中stata裡的表格——右鍵——點擊“copy table”——粘貼到Word文檔中——選中,利用“文本轉化成表格”
框線要求:選中表格,調整邊框線——上下框線1.5磅,中間橫框線0.5磅,中間豎框線0.5磅,左右外側無邊框——選中表格右鍵——自動調整——根據窗口調整表格
描述性統計如果是0.12的小數,小數點前邊會沒有0,只是“.12”所以需要手動添加。
一條回歸命令導出一個回歸結果,也就是每個導出的回歸表格只有兩列,所以需要將各回歸結果進行合併。我們可以選擇最長的一列作為基準,然後將其他的依次加入此表格中(在此操作中,本人覺得WPS的Word很好用)。注意變量名與數據的對應,然後再刪除空白行,邊框的要求同上。 (如果你沒實操過,可能覺得我在瞎說八道,算是吧.........)
導出每個表格時,一定記得手動copy “R-squared、Adj R-squared”的信息,在手動添加到表格後邊,利用固定效應命令的,可以把那些表量名改為中文,處理如表3。再把表格美化一下,比如將變量名處的表格合併居中,之後再上註釋就OK了。
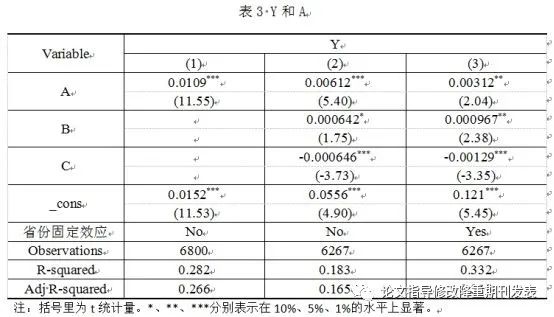
一般註釋都是比正文小一號的字體,表名字體跟正文一樣。中文用宋體,英文,數字用新羅馬(Times New Roman)。表格後邊記著空一行再接正文。
六、論文內容
我寫的時候對論文框架也迷茫了,因為不同論文結構也有細微差別,然後然後我就糾結到底到該模仿哪篇的結構,糾結的我。可親可愛導師幫我們拎了一個大框架,實在糾結的同學們可以參考一下。
論文模板
一.引言
二.文獻綜述
(一)
(二)
(三)
三.理論分析與假設
(一)A與B
(二)
(三)
四.研究設計
(一)數據來源與變量界定
(二)回歸模型與方法
五.實證檢驗與結果分析
(一)描述性統計
(二)相關性檢驗
(三)回歸分析
(四)穩健性檢驗
六.結束語
參考文獻
謝謝各位看完,祝大家論文順利! !

END


往期回顧


文章為用戶上傳,僅供非商業瀏覽。發布者:Lomu,轉轉請註明出處: https://www.daogebangong.com/zh-Hant/articles/detail/How%20to%20write%20an%20empirical%20paper%20Dry%20goods%20are%20recommended%20for%20collection.html
 支付宝扫一扫
支付宝扫一扫 
评论列表(196条)
测试