Cloud computing gives IT resources scalable power, thereby integrating computing power and providing a stage for various new technologies to perform. It also accumulates rich resources for society and provides underlying technical support for big data and artificial intelligence. Big data technology will not only help people discover the value of data through the storage, processing, processing and analysis of data, but also provide rich and high-quality data resources for artificial intelligence. Artificial intelligence technology is the key to the intelligence of human society. In addition to the Internet, it will be another technology that has a profound impact on mankind. The power it unleashes will once again completely change our lives.
However, these three technologies are inseparable from one key point, which is distribution. If we cannot deeply understand distribution, we will actually not be able to truly understand cloud computing, big data and artificial intelligence. The 2018 UCan Afternoon Tea Finale, with the theme of "Returning to the Cloud Core, Serving the Distributed Practice of Big Data and AI", technical experts from UCloud, Oris Data, and Kyligence discussed the distributed design of big data and AI platforms. Practice was discussed and shared in depth.
UCloud Luo Chengpair: A new generation of public cloud distributed database UCloud Exodus
Since its launch for commercial use, UCloud has been operating stably for 6 years, covering 29 availability zones around the world and serving tens of thousands of enterprise users. At present, the number of UCloud cloud database instances reaches tens of thousands, the data volume of the entire system exceeds the data volume by 10PB+, the number of single-user instances reaches 6k+, and the single-user data volume is 1.8PB. Such a rapidly expanding data scale undoubtedly brings unprecedented challenges to the capacity limit, cost performance, performance, and compatibility of cloud databases. Luo Chengdui, head of UCloud's relational storage R&D department, believes that to solve these challenges, it is necessary to change the traditional cloud + database thinking and achieve symbiotic reuse of the data layer and infrastructure layer.
Under a traditional distributed database, the database can be simply abstracted into two layers. The first layer is the SQL layer, and the second layer is Storage. The typical implementation of the SQL layer is based on distributed storage. This solution can be compatible with various protocols and infinitely expandable. There are no distributed transactions and distributed join problems, but its shortcomings are also obvious. The SQL layer has problems with multi-node cache consistency and distributed locks; the most typical implementation of the Storage layer is based on the Sharding architecture, which can also be performed under this architecture. Infinite expansion, but the protocol cannot be 100% compatible, and there are distributed transactions and distributed Join problems.
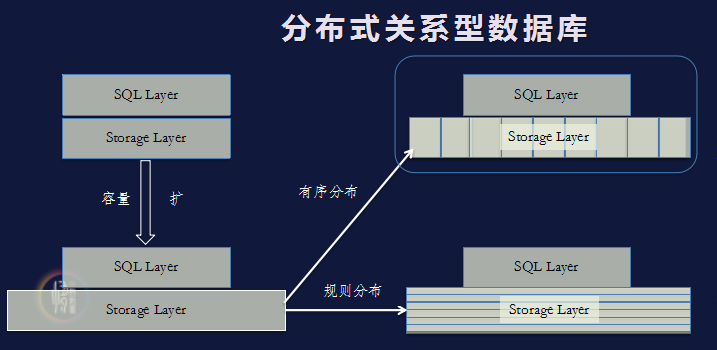
Generally speaking, the wireless expansion problem can be achieved based on the traditional distributed storage solution, but its disadvantage is that the protocol is incompatible, and there are distributed transactions and distributed Join problems. Against this background, UCloud is based on a high-performance distributed storage architecture and integrates the latest software and hardware technologies to develop a new generation of public cloud distributed database Exodus.
Exodus supports the mainstream open source database MySQL and is fully compatible with various protocols, including RDMA, Skylake, SPDK, user-mode file systems, etc. The computing layer uses a deeply customized MySQL InnoDB engine, and the architectural design supports one master and multiple slaves. Through these designs, Exodus solves the four major pain points of cloud database capacity, performance, cost performance, and compatibility in one fell swoop.
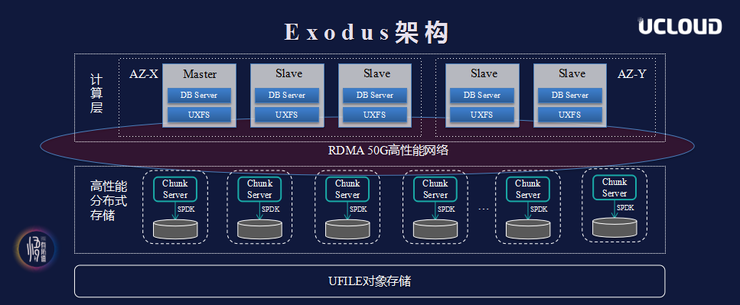
The system is based on the user-mode protocol stack and is more adaptable to new hardware dividends. The single-core theory can reach one million IOPS, reducing the overhead of traditional kernel interrupts and context switching. The latency overhead of the network is inherently large in traditional distributed storage. The RDMA protocol (RoCE) network based on converged Ethernet is essentially a network protocol that allows remote direct memory access through Ethernet, which can implement Zero Copy.
The bottom layer adopts the AppendOnly mode. Compared with the traditional in-situ update method, it is more friendly in terms of EC data security and Snapshot implementation. It also has better detection methods for disk abnormalities such as silent errors. On the IO path, the CRUSH algorithm is used to calculate the placement of all shards, without the need for caching or index query. LSMT Log-structure merge tree supports random reading and writing through LSMT.
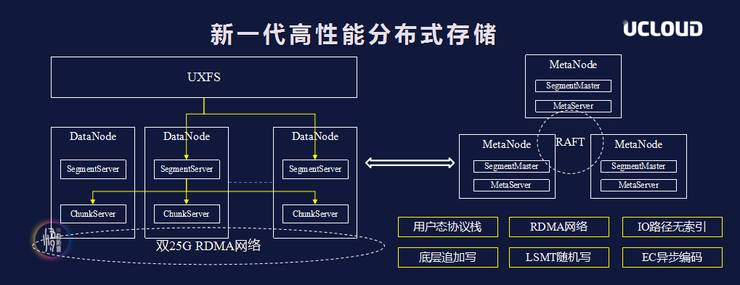
Traditional distributed storage generally uses a three-copy approach to ensure data reliability (10-11 nines). After Exodus adopts the bottom-layer append-write approach, it can use EC and compression without affecting reliability. The data copy cost is reduced from 3 to about 1 while ensuring safety. The computing layer uses deeply customized MySQL+InnoDB, which can directly reuse public cloud distributed storage products (such as UCloud block storage product UDisk).
Based on this architectural design, Luo Chengdui judged that the underlying distributed storage products of future cloud platforms will achieve ultimate optimization in the IO path, and the underlying distributed storage of mainstream cloud platforms will achieve microsecond-level latency and millions of IOPS. Sufficient to support high-performance services (such as databases).
UCloud Fan Rong: AI PaaS platform practice
How to effectively reduce costs and speed up the trial and error of AI solutions is an issue that every company that wants to commercialize AI algorithms needs to consider. UCloud LabU deep learning development engineer Fan Rong combined the technical practice of UCloud AI PaaS platform to describe how UCloud provides public cloud users with an out-of-the-box AI development, testing, and deployment integrated environment.
Before the AI PaaS platform is launched, the first challenge most companies face is the complexity of basic environment construction: diverse choices of AI frameworks, many variables of the environment, many variables of the hardware, and many variables of the underlying data storage. The above cross-combination directly leads to a situation: if it is necessary to build a complete system of software and hardware combination, and each business line has different needs, multi-environment maintenance will become extremely painful. Secondly, the compatibility of the algorithm needs to be considered when building the AI system. The platform needs to have scalability, elastic scaling capabilities, disaster recovery capabilities, etc. to cope with the horizontal and vertical expansion of the platform. Therefore, a complete AI PaaS platform needs to have the following characteristics:
Algorithm compatibility: better compatible with various AI frameworks and algorithms;
Horizontal scalability: supports CPU, GPU, S3, NFS, HDFS and other storage;
Vertical scalability: The platform has horizontal scalability to support the continuous expansion of business scale;
High availability: with elastic scaling and disaster recovery capabilities;
Environment migration: Public cloud capabilities can be migrated to private cloud environments.
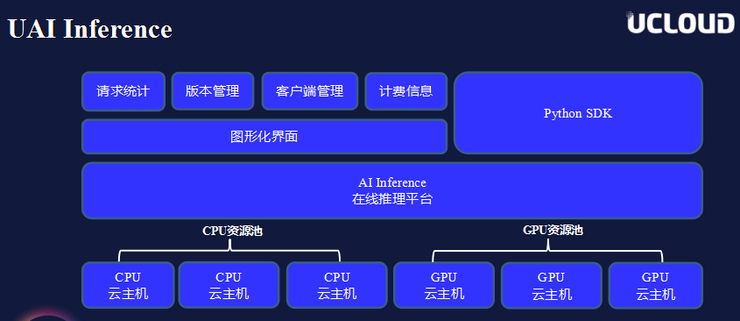
Based on the above five elements, UCloud has built its own AI basic platform, which includes two core services: AI Train and AI Inference. As shown in the figure below, the uppermost layer is the training log, service status, TensorBoard framework and Jupyter. Next is the graphical interface, which mainly completes some basic deployment operations. The right side is the Python SDK interface, and below the access layer It is the AI Train and AI Service at the core of the platform, and the bottom layer encapsulates all computing nodes and storage access.
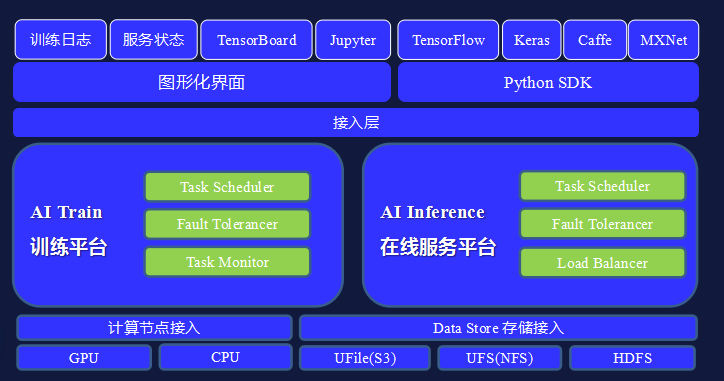
In terms of AI Train, in order to achieve horizontal scalability, UCloud not only provides stand-alone training, but also provides distributed training capabilities. That is to say, in addition to providing single-node programs, as long as users meet the development framework requirements, the platform can also automatically deploy distributed frameworks, which can greatly reduce training time and improve efficiency under massive training services. In addition, the platform also provides interactive training methods. Users can interact with the cloud space in real time and obtain real-time training results on the cloud.
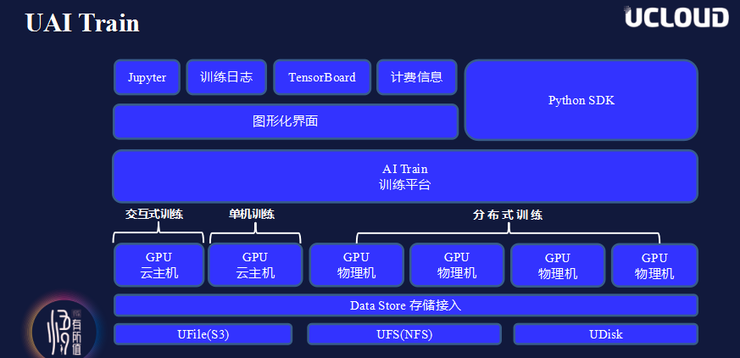
In addition, UCloud has designed two major resource pools in terms of AI Training and AI Inference platform computing power. If users have relatively low computing power requirements and want to achieve good elastic expansion capabilities, they can use CPU resource pools. If the computing power requirements are relatively high, a GPU resource pool can be used, so that optimal support can be provided according to different user computing power needs.
UCloud Ding Shun: Design and implementation of database high availability disaster recovery solution
There are a variety of database high-availability solutions in the industry. Each solution has its own characteristics and shortcomings. Ding Shun, a senior storage R&D engineer from UCloud, gave a detailed explanation of the technical implementation and advantages and disadvantages of these solutions, and shared UCloud cloud The design and implementation of the high-availability disaster recovery solution of the database product UDB, as well as some experience and insights in the large-scale high-availability database operation and maintenance of the UDB product.
According to Ding Shun, the industry's typical high-availability architecture can be divided into four types: the first, shared storage solution; the second, operating system real-time data block replication; the third, database-level master-slave replication; third, Highly available database cluster. Each data synchronization method can derive different architectures.
The first is shared storage. Shared storage means that several DB services use the same storage, one is the main DB, and the others are backup DBs. If the main service crashes, the system starts the backup DB, becomes the new main DB, and continues to provide services. Generally, the SAN/NAS solution is mostly used for shared storage. The advantage of this solution is that there is no data synchronization problem, but the disadvantage is that it requires relatively high network performance.
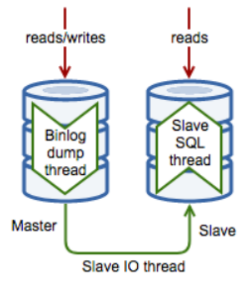
The second type is real-time data block replication by the operating system. A typical scenario for this solution is DRBD. As shown in the figure below, after data is written to the database on the left, it is immediately synchronized to the storage device on the right. If the database on the left crashes, the system directly activates the database storage device on the right to complete the disaster recovery switch of the database. This solution also has some problems. For example, the system can only have one data copy to provide services, and cannot realize read and write separation; in addition, the disaster recovery time required after the system crashes is long.
The third type is database master-slave replication. This solution is a more classic data synchronization mode. The system uses one master database and multiple slave databases. The master database synchronizes the database logs to each slave database, and the slave databases play back the logs respectively. Its advantage is that one master database can connect to multiple slave databases, and it can easily realize separation of reading and writing. At the same time, because each standby database is being started, the data in the standby database is basically hot data, and disaster recovery is a must. Switching is also very fast.
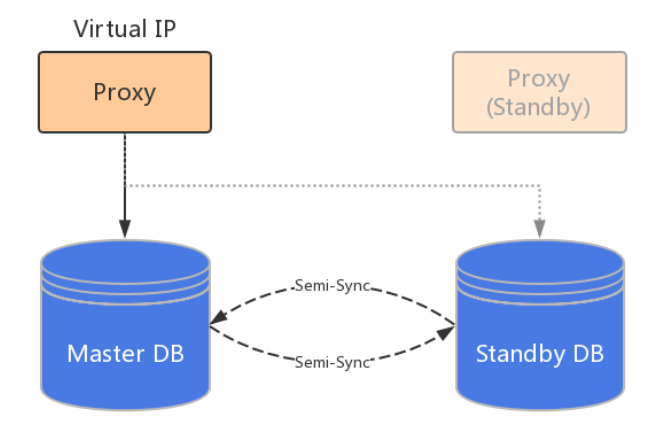
The fourth type is database high availability cluster. The first three are to achieve high availability through the replication log mode, and the fourth solution is to do data synchronization based on the consistency algorithm. The database provides a multi-node consistent synchronization mechanism, and then uses this mechanism to build a multi-node synchronization cluster. This is a popular high-availability cluster solution in the industry in recent years.
UCloud combines many factors such as native MySQL compatibility, coverage of different versions, and different application fields, and finally chooses to implement a high-availability architecture based on database master-slave replication. Based on the original architecture, it uses dual-master architecture, semi-synchronous replication, GTID and other measures are used to perform a series of optimizations to ensure data consistency and realize automatic addressing of logs.
Automated operation and maintenance is a difficult point in high-availability databases. In addition to daily routine inspections, UDB also conducts regular disaster recovery drills to check whether data is lost and maintains consistency in different scenarios, and also sets recording logs and alarms. systems, etc., so that problems can be discovered as soon as possible, trace the root cause of the problem, and find the best solution.
Osi Data Li Mingyu: Data distribution algorithm in distributed storage
Data distribution algorithm is one of the core technologies of distributed storage. It not only takes into account the uniformity of data distribution and addressing efficiency, but also considers the cost of data migration when expanding and reducing capacity, and takes into account the consistency and availability of copies. Li Mingyu, founder and CTO of Oris Data, analyzed the advantages and disadvantages of several typical data distribution algorithms on site, and shared some problems encountered in specific implementation.
Consistent hashing algorithm has been developed because it can locate data without table lookup or communication process, the computational complexity does not change as the amount of data increases, and it has high efficiency, good uniformity, and small amount of data migration when adding/reducing nodes. People like it. However, in practical applications, this algorithm also encounters many challenges due to its own limitations. For example, in the "storage blockchain" scenario, it is almost impossible to obtain a global view, and it is not even stable for a moment; enterprise-level IT scenarios Under this situation, there is the problem of reliable storage of multiple copies, and the cost of data migration is huge.
The so-called storage blockchain can be understood as distributed storage (p2p storage) + blockchain. It uses token incentives to encourage everyone to contribute storage resources and participate in building a worldwide distributed storage system. Because a large number of users need to be encouraged to participate voluntarily, it will involve addressing and routing problems of hundreds of millions or even billions of nodes. Currently, the main solutions in the industry include Chord, Kademlia, etc. However, the Chord algorithm is less efficient and will produce higher delays. Finger tables can be used. In addition to recording the current node and next node positions, it also records the position of the current node 2^i+1, reducing computational complexity and ultimately reducing latency. .
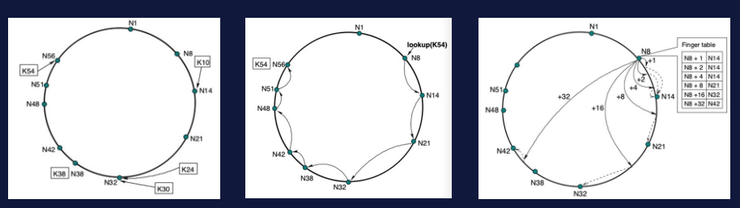
In enterprise-level IT scenarios, data distribution algorithms include Dynamo, Ceph's CRUSH, Gluster's Elastic Hashing, and Swift's Ring. These algorithms all have similar characteristics. First of all, they are based on/draw on consistent hashing, and the amount of data migration is small when adding/reducing nodes. Secondly, the modeling of the physical topology of the data center (Cluster Map) is introduced, and multiple copies of data/EC shards are distributed across fault domains/availability zones. In addition, these algorithms can also assign weights to nodes, data distribution and capacity/performance matching to assist in capacity expansion.
Generally speaking, these two types of solutions are based on consistent hashing algorithms, but they have different improvement directions because of different needs. The enterprise level pays more attention to the distribution of replica fault domains; while for P2P storage, it pays more attention to ensuring that data can be addressed within a valid time when nodes exit and join at any time.
Kyligence Liu Yiming: Unleash big data productivity
In the face of a rich technology product stack, big data analysis scenarios still face problems such as high technical thresholds, talent shortages, and long project development cycles. How the IT department can transform from a passive business enabler to a business enabler, and how the business department can better understand data and mine the value of data through excellent tools, are questions that every data team and IT team need to think about. Liu Yiming, Vice President of Kyligence Cloud and Ecological Cooperation Department, talked about the design thinking and best practices of Apache Kylin technology based on the above issues.
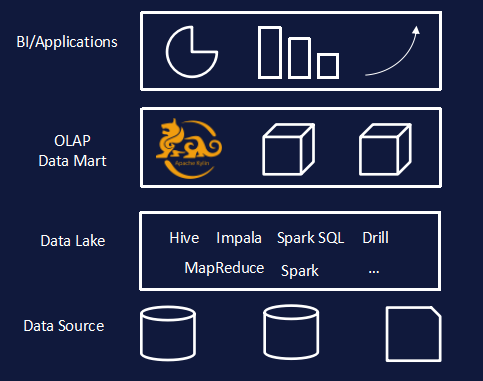
Apache Kylin is an open source distributed analysis engine that provides SQL query interface and multidimensional analysis (OLAP) capabilities on Hadoop (Kylin can be defined as OLAP on Hadoop). According to reports, it is the first open source project contributed entirely by Chinese people to the top international open source community, and also the first top Apache open source project from China.
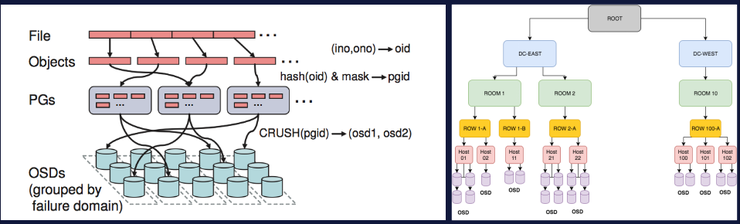
As an OLAP engine, Apache Kylin includes obtaining source data from data sources (Hive/Kafka, etc.), building multi-dimensional cubes (Cube) based on MapReduce, and making full use of the columnar characteristics of HBase to store cube data in a distributed manner, providing standard SQL parsing and Query optimization, as well as multiple modules such as ODBC/JDBC driver and REST API.
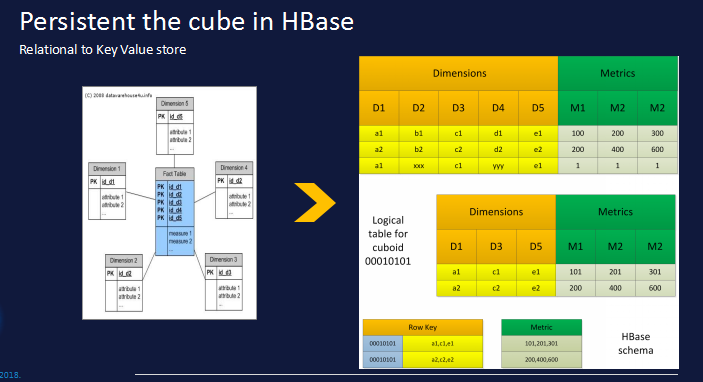
As shown in the figure below, Kylin is based on HBase column storage. The calculation result set is stored in HBase. The original row-based relational model is converted into column storage based on key-value pairs. The dimension combination is used as Rowkey, and query access is no longer required. Expensive table scans are required. Dimension values are highly compressed through encoding algorithms (dictionaries, fixed lengths, timestamps, etc.). Indicators are stored through Column, which can flexibly and unlimitedly increase the number of indicators. In addition, pre-calculated results are also high-speed and high-concurrency. Analysis brings possibilities.
Most Hadoop analysis tools are friendly to SQL, so it is particularly important that Apache Kylin has a SQL interface. The SQL parser used by Kylin is the open source Apache Calcite, which supports almost all SQL standards. Hive also uses Calcite.
Unlike other SQL ON Hadoop, Kylin mainly uses pre-computation (offline computing) implementation. Before using it, the user first selects a collection of Hive Tables, and then builds an offline Cube on this basis. After the Cube is built, SQL queries can be performed. Use offline calculations to replace online calculations. By completing complex and computationally intensive work in the offline process, the amount of online calculations will become smaller, and query results can be returned faster. In this way, Kylin can achieve higher throughput with less calculations.
Due to space limitations, this article only compiles some of the wonderful speeches at the scene. Interested readers can click to read the original text and download the lecturer's PPT for in-depth understanding! Lei Feng Network Lei Feng Network Lei Feng Network
Articles are uploaded by users and are for non-commercial browsing only. Posted by: Lomu, please indicate the source: https://www.daogebangong.com/en/articles/detail/cong-fen-bu-shi-shi-jiao-kan-da-shu-ju-yu-AI-ping-tai-de-gou-jian.html
 支付宝扫一扫
支付宝扫一扫 
评论列表(196条)
测试