
< strong>Target crowd: Have a certain reading foundation for empirical papers, and have a basic understanding of its structural framework and the functions of each part.
Purpose of writing: This article is not a tutorial for empirical papers, but a reminder of the difficulties you and I may encounter in the middle, and Pay tribute to the hair that fell out in those years.
1. Identify research questions
(1) Reading literature
First of all, you have to have a general direction, which can be your own interest, or under the guidance of a mentor, but it is best to use both Combination, otherwise, after seeing so many dry goods, I choose to explode in place. Generally, a core word is determined, and then related documents are downloaded on HowNet. When I first started to read literature, it was very slow, and you could hardly understand what he meant, it didn’t matter, everyone was like this. But the first few articles, you'd better read them in order, from the beginning to the end, to understand its mechanism of action, how one variable affects another variable, the model must be focused on, this is what you need to learn from, Including the quantification of variables and the source of data, no matter how beautiful you think, the data cannot be found, or it is useless. When you read it for the first time, you can make appropriate marks in the literature, and you can also write down your impressions. However, after reading the entire article, be sure to extract the most critical ones! You can quickly browse the whole article, focus on the marked places, and extract them! Record it! come down! Please remember the advice I love, otherwise, you will forget (honey smile)....My excerpted content (for reference only): title and author information (reference format), mechanism of action, hypothesis, model , variable quantification, and data sources. It is recommended to extract more than 20 articles, and then properly classify and summarize the literature you have read, and you will gradually discover the similarities between these literatures. Remember to properly review the literature you have read before when reading literature, you may be inspired when reading a certain article, remember to write it down, otherwise you will forget...
(2) Determine the basic model
The key is to determine the main explanatory variables and the explained variables. After doing the above work, you need to reread the information you have extracted from the papers, and then you can properly combine innovations, select core variables, and then further search for relevant literature to continuously supplement and optimize. In my opinion, the determination of the problem is almost identical to the determination of the basic model.
Different documents may adopt different quantification methods for the same variable. After determining the main variables, you can choose the most suitable quantitative method for your paper in these literatures, and you can also prepare for the subsequent robustness test.
2. Download data
The next step is to find the data. You have to know the data corresponding to each of your variables, and then go to the database to find it. The research questions of my thesis are related to enterprises, so the relevant information of listed companies can be used. The resources at hand are the Wind financial database (Wand) and the CSMAR database (Guotai’an). The following is my opinion on the enterprise data of these two databases. Because the stata software is used for data processing later, there are certain requirements for importing data, so the convenience of data sorting must also be considered. The Wonder database can only be used on a specific computer. Download data from Wonder. A data sheet can download various information of a company at the same time, but you can only download information at a time cut-off point, which is the style of cross-sectional data. Your panel If the data spans several time points, you need to download several data tables, and then merge the downloaded data tables (pasting and copying continuously). Guotaian is a mobile webpage type, as long as there is a website, the account can be used anytime and anywhere, and the panel data style can be directly downloaded from it, but different information of the enterprise may exist in different data sheets, that is, after downloading the data, You also need to merge and match, and it is more difficult, because the number of samples in different data tables may not be exactly the same. If it is cross-sectional data, or panel data with a small number of time periods, it is recommended to use Wonder. If the panel data spans a large number of time periods, it is recommended to use Guotaian. The premise is that you have a choice.
My data is quarterly data, and it spans several years, so I choose Guotai’an (I can say that my Yangou is seeing the interface of Guotai’an Instantly became a fan)! But when the data was sorted out in the later stage, the matching between different data tables still tortured me to death, so I didn’t think about whether Wonder is better, but I really have no love for his interface, forgive me for being irrational .
Friendly reminder: When downloading data, don't worry about whether the data information you download will be too much or whether the time span will be too large. Because of the lack of some information, I don't know how many times I reworked when sorting out the report, and I just cried. Halfway through the arrangement, I found something wrong, and went back to download again, over and over again... Especially the information about data statistics must be downloaded clearly, such as stock code, report deadline, report type, etc.
Stata import data format
When Excel is processing, the first row is the variable name, and different columns refer to different information of the sample. The first column is the stock code, the second column is the year, and the third column is the quarter, and then you can enter other information such as the company's net profit margin in turn. The information of different enterprises at different time points is entered in each row. Of course, stata with disordered order between lines can also be identified. It is recommended to use English for the variable name, Chinese is not recognized.
3. Data processing
Data downloaded from Guotaian It may belong to different report types. I didn’t download the report type information for the first time, and then some variables had two different data at the same time point. . There are two report types: A and B. A represents the report of the parent company, and B represents the report of the head office. The downloaded data are mixed together, so we generally classify this first, and generally use the report data of the parent company for problem research.
(2) Data deletion
1. Delete the data of financial enterprises: the leverage ratio of financial enterprises is large, and the situation of each indicator is very different from that of other enterprises, so when studying enterprise issues, it is generally Deleted by default.
2. Delete blank data: If a certain data of this month of the enterprise is missing, the entire row of data needs to be deleted
3. Delete unreasonable data: You need to judge the reasonable range of each indicator, maybe the data of this indicator cannot have a negative value, maybe it is impossible Greater than one, you need to delete data outside the reasonable interval
4. Delete garbled characters: Some data is obtained through calculations between data, so it is possible to get garbled characters, which also need to be filtered out and deleted
When deleting data, you can use the filtering function in Excel skillfully. This is to admire the 2007 version of office, which can filter out a certain data for partial deletion, but WPS cannot.
(3) Data integration
At this time, it is necessary to integrate the data scattered in different Excel tables into one table. The blank data must be deleted before this work, because, When you use functions such as vlookup to match the tables together, the blank spaces are automatically filled with 0. When using Excel for data processing. Be sure to ask Du Niang, it can be a trivial question, you will find that Excel can still operate like this! Don't foolishly do it yourself. (I was like this at the beginning, my heart hurts so much that I can’t breathe, Du Niang is stronger than you think, Excel’s coquettish operation is not something you and I can worship)
(4) Data transformation
Stata only recognizes numerical data, only English and Arabic numerals, so unqualified ones are all marked red when you import them into stata. Several situations I encountered:
Stock code 000001,000002——NO; date 2018/01/01/ , 20180101——NO; 78%——NO; text data— — not even
As for how to convert it into a standard format in a specific situation, I would like to ask Du Niang, please do not directly convert it manually! I have used vlookup, and it often fails to match in the middle, especially when using text information, you need to compare whether the matching IDs are the same, for example, Guangdong and Guangdong provinces cannot be used; the processing of dates has been done using the "Sort Columns" in Excel ", left and so on.
4. Use stata for data processing
As I said before, I use the panel data of various companies for my research questions, so the following are just the common commands I use to process panel data when I use stata introduce. Again, this is not a stata tutorial. You need to understand the basic operations of stata, including how to import data and install software.
(1) command
Clear.......................... ................................................... ................................clear data
generate quarterly=yq(year,
quarter).......................... ...................................Define time (I use quarterly data so it is defined as quarterly, if it is Monthly is converted to monthly)
xtset x1 quarterly.......................... ...................................Define the data as a "panel" form, x1 is a number similar to cross-sectional data, like each person All have different IDs, and different listed companies also correspond to different stock codes
gen
x1_=l.x1.......................... ................................................... .....Lagging variables for the first period Reminder: l. Follow the variable name directly, no spaces are allowed
sum x1 x2 x3 x4
.......................... ................................................... .......... Descriptive statistics include sample information such as sample number, maximum value, mean and variance, etc. The export of this result needs to be directly copied and pasted (details will be introduced later)
pwcorr_a x1 x2 x3 x4, star1(0.01) star5(0.05) star10(0.1).......... ..........Correlation analysis star (.01) The brackets indicate the significance level, and the processing method of the result export is the same as that of descriptive statistics
xtreg y x1 x2 x3 x4, fe................................... ................................................... .. The fixed effect regression command y is the explained variable, x is the explanatory variable fe means the fixed effect, when using the fixed effect, those variables that do not change over time in the regression results will not have coefficients, only significant levels will appear, such as a person gender (smile), business nature, location, etc.
xtreg y x1 x2 x3 x4,
re........................... ................................................Random Effects Regression Command When using random effects, there will be coefficients for each variable in the regression results. Forgive my ignorance, I still don’t know how to explain the meaning of different effects
esttab using y8.rtf ,star(* 0.1 ** 0.05 *** 0.01).......... ...................................Export regression results y8 is the name you want to export to the file, this command can only export regression results, but Descriptive statistics and correlation analysis results cannot be exported
If you find that the command input has no results, you can check whether the spaces in the command are correct and whether the capitalization is correct. Stata seems to only recognize English lowercase.
(2) Trouble
If you find that the data you made for the first time is not significant (the P value of the data I ran for the first time was 0.9, and I want to die, But keep smiling), don't be sad and don't be impatient! Because tomorrow's you will be even worse... take back the poisonous chicken soup, and I recommend several tranquilizers to everyone (as for whether these methods are scientific, I can't comment, I only know that these methods are quite easy to use).
Indentation processing
ssc install
winsor2.......................... ................................................... ..Installation process for installation (At the time of Baidu, I foolishly thought that I was really going to download some installation package, and I studied it for a while, and then I found out in despair that when you enter this command, it is called installation. ......)
winsor2 x1 x2 x3 x4, replace cut(1 99)
winsor2 x1 x2 x3 x4, replace cut(1 99) trim
After indenting the input, you need to enter the regression command again xtreg y x1 x2 x3 x4, fe
2. Packet processing
The data can be grouped according to certain standards, such as according to the nature of the enterprise, it can be divided into state-owned enterprises, private enterprises, foreign capital, etc.
3. Delete data
This does not mean that you can delete the sample data at will, but choose the interval you want to study. If your sample size is large enough, you can adjust the year of the data to be studied, for example, change 2012-2018 to 2015-2018; you can also choose a specific category in the grouping to study, but then your theory will be different. have to be interpreted accordingly; you can also change the time frequency from quarterly to monthly or yearly.
The meaning of the specific command and why it should be handled in this way, please figure it out by yourself (cross it out, understand it yourself), I just don’t know what to do when running the data If we are at a loss, let's lead the way a little bit and avoid some detours, otherwise we will have to start all over again after working for a long time. Still the same sentence, I suggest that if you have any questions, you can ask Du Niang or consult related books, or ask the gods for help, don't just go straight or give up.
As for why not write more specifically, because.......... ...........................................lazy
Five, thesis layout
I am afraid that I have been poisoned by typesetting, and now I need to spend some extra time on typesetting. Song typeface, small four, and line spacing are fixed at 22 points. The first line is indented two spaces (smile, I can't help myself)! Every school and journal has different requirements for the format of papers, so there is no uniform standard. But just to remind everyone, adjust the page margins of the page layout first, otherwise the table you finally adjusted will spread across pages again! It is recommended that you read the typesetting requirements of the paper in detail first. Don’t adjust one by one, and it is not recommended to use a format brush. When modifying the format, it is recommended that you adjust the formatting marks in the view, so that symbols such as spaces and carriage returns can be displayed in the document.
(1) References
sample:
[1] Li Houjian, Zhang Zongsheng. The tenure of local officials, corruption and enterprise R & D investment [J]. Scientific Research, 2014, 32(05): 744- 757.
Explanation:
1. Use English format except for the text part;
2. There must be a space after each punctuation mark;
3. Except for [1], other [2][3] are generated with carriage return
4. [1]-[9] is set to indent the first line with 1.5 points; after [10], it is set to 2 for alignment
5. If you use HowNet to export, remember to delete the last export time and other redundant information
(2) Form
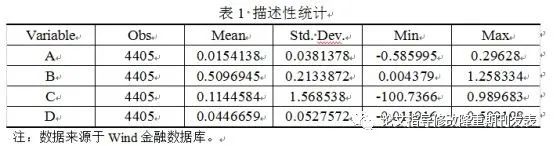
1. Descriptive statistics
Export: select the table in stata - right click - click "copy table" - paste into a Word document - select, use "text conversion form"
Frame line requirements: select the table, adjust the border line - 1.5 points for the upper and lower frame lines, 0.5 points for the horizontal frame line in the middle, and 0.5 points for the vertical frame line in the middle, There are no borders on the left and right sides - right click on the table - auto adjust - adjust the table according to the window
If the descriptive statistics is a decimal of 0.12, there will be no 0 before the decimal point, just ".12", so it needs to be added manually.
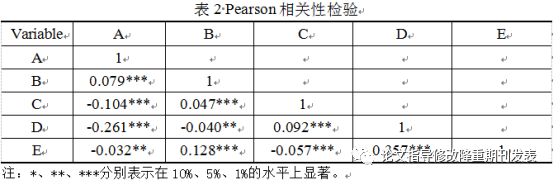
A regression command exports a regression As a result, each exported regression table has only two columns, so the regression results need to be combined. We can choose the longest column as the benchmark, and then add the others to this table in turn (in this operation, I think WPS Word is very easy to use). Pay attention to the correspondence between the variable name and the data, and then delete the blank line. The requirements for the border are the same as above. (If you haven't practiced it, you may think I'm talking nonsense, so be it......)
When exporting each table, you must remember to manually copy the "R-squared, Adj R-squared" information, manually add it to the back of the table, and use the fixed For the effect command, you can change the names of those meters to Chinese, as shown in Table 3. Beautify the table again, such as merging and centering the table at the variable name, and then add a comment and it will be OK.
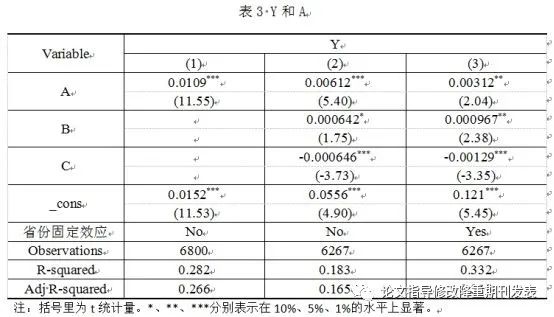
Comments are generally written in a font smaller than the text, and the font of the table name is the same as the text. Song typeface is used for Chinese, Times New Roman is used for English, and Times New Roman is used for numbers. After the form, remember to leave a blank line before the text.
6. Thesis content
When I was writing, I was also confused about the structure of the paper, because the structure of different papers also has subtle differences, and then I was entangled in which structure to imitate , I am entangled. The dear and lovely tutor helped us carry out a big framework, students who are really struggling can refer to it.
Thesis template
One. introduction
Two. literature review
(1)
(two)
(3)
3. Theoretical Analysis and Hypotheses
(1) A and B
(two)
(3)
Four. Research design
(1) Data source and variable definition
(2) Regression model and method
Five. Empirical testing and result analysis
(1) Descriptive statistics
(2) Correlation test
(3) Regression analysis
(4) Robustness test
Six. conclusion
References
Thank you for reading, I wish you all the best papers! !

END


Past Review


Articles are uploaded by users and are for non-commercial browsing only. Posted by: Lomu, please indicate the source: https://www.daogebangong.com/en/articles/detail/How%20to%20write%20an%20empirical%20paper%20Dry%20goods%20are%20recommended%20for%20collection.html
 支付宝扫一扫
支付宝扫一扫 
评论列表(196条)
测试