< span style="font-size: 0.882em;">"Open Source Selection" is a column where we share high-quality projects in open source communities such as Github and Gitee, including technology, learning, practical and various interesting content. This issue recommends an open source OCR image-to-text recognition software - Umi-OCR.

Features
- Free: All codes of this project are open source and completely free.
- Convenience: decompress and use, offline operation, no network required .
- Batch: Images can be imported and processed in batches, and the results can be saved to Local txt, md, jsonl files in multiple formats. You can also take instant screenshots for identification.
- Efficient: Adopt PaddleOCR-json C++ recognition engine. Usually faster than online OCR services as long as the computer is powerful enough.
- Precise: Use the PPOCR-v3 model library by default. In addition to being able to accurately recognize regular text, it also has a good recognition rate for scenarios such as handwriting, incorrect orientation, and messy backgrounds. You can set the ignore area to exclude the watermark, and set the post-processing of the text block to merge the typesetting paragraphs to obtain a regular text.

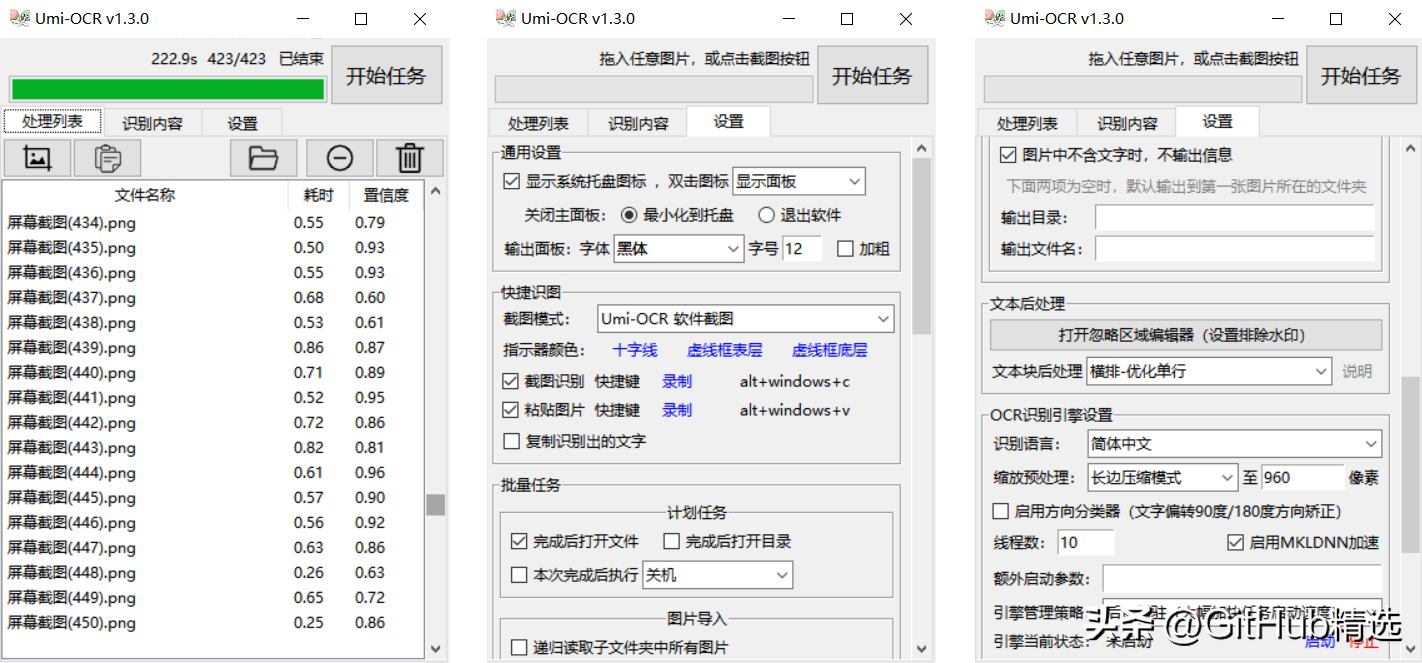
Easy to get started
Screenshot recognition
Click the screenshot button or customize the shortcut key to evoke screenshot recognition.
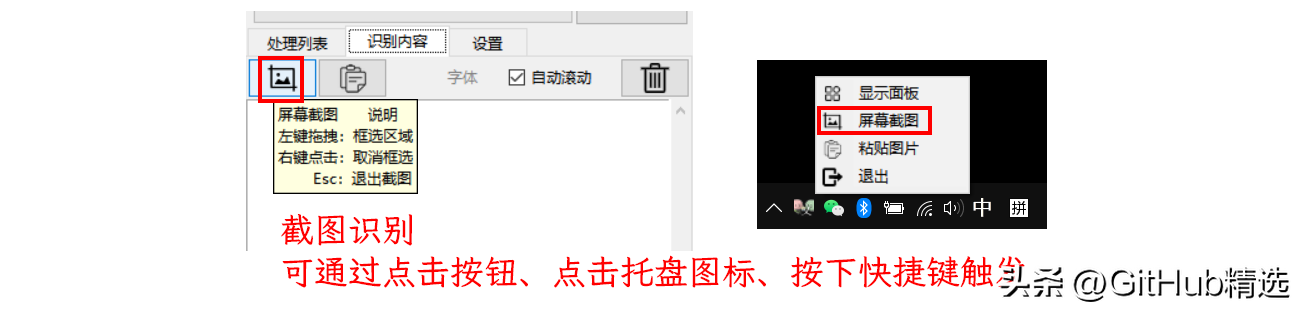
Paste the picture to the software
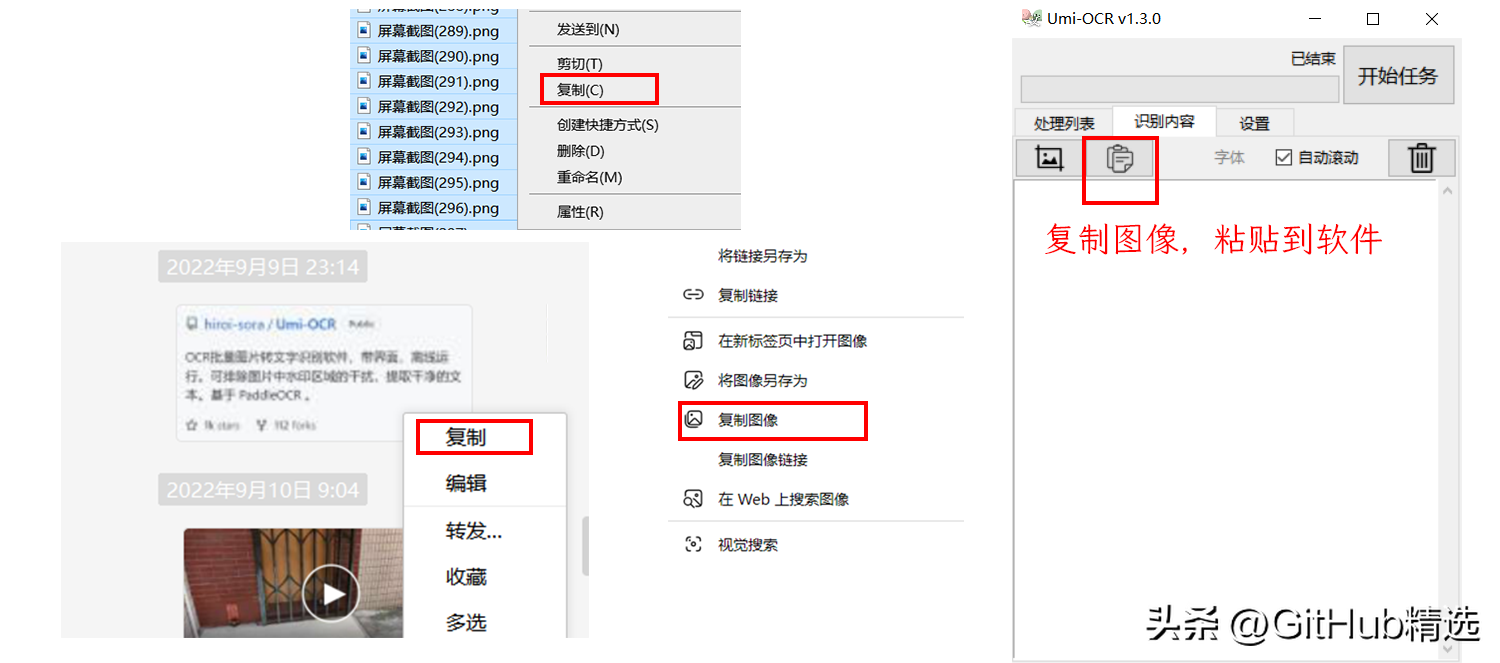
Copy the picture anywhere (such as file manager, web page, WeChat), click the paste button on the software, and it will be automatically recognized.
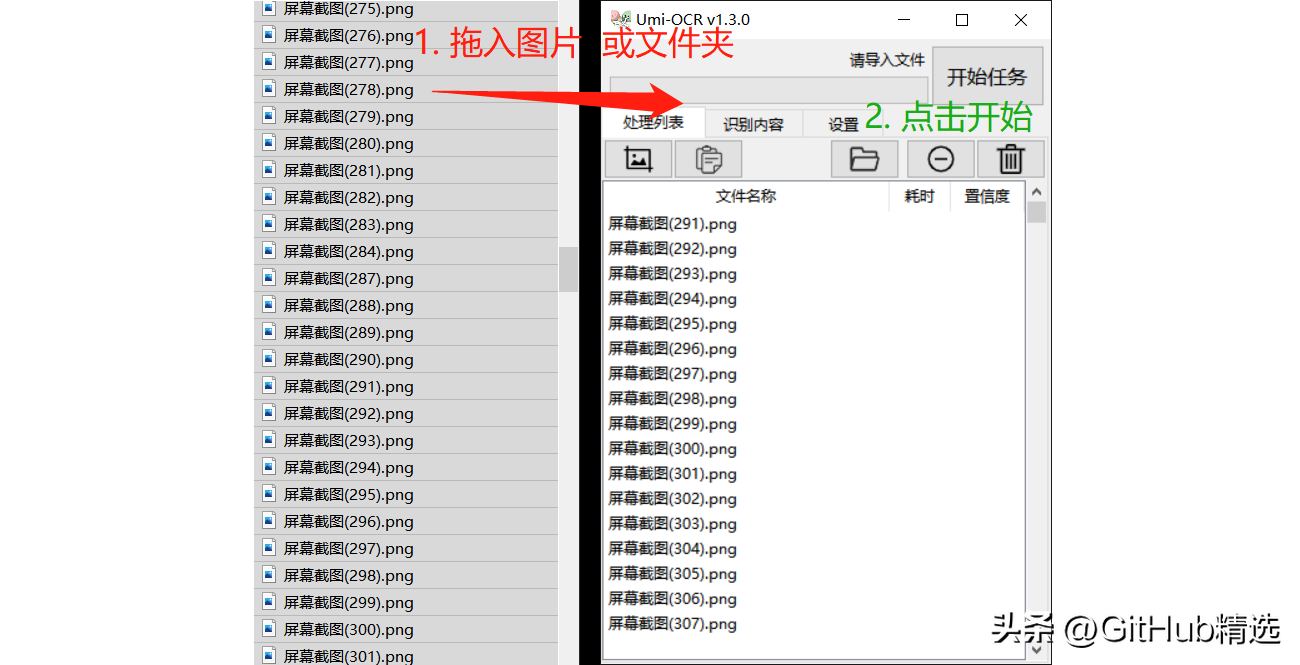
Batch recognition of local image files
Drag pictures or folders into the software to convert text in batches. You can also click the button to open the browser window to import.
The recognition result will be saved locally. Optionally generate plain text txt files, Markdown files with links, raw information json files and other formats. Perform shutdown/standby after configurable task completion.
Text block post-processing (typesetting optimization)
The text recognized by OCR is divided into "blocks". Usually, a line of text is divided into one block, and sometimes a line is mistakenly divided into multiple blocks, which brings inconvenience to reading. Text block post-processing is the process of reprocessing the text block, merging the text in the same line or the same paragraph, and sorting them in the correct order.
The following figure shows which processing scheme should be used for different typesetting:

Ignore area features
Ignore area is a special function of this software, which can be used to eliminate the interference of watermark in the picture, so that only the required text is left in the recognition result.
Easily exclude watermarks from video screenshots
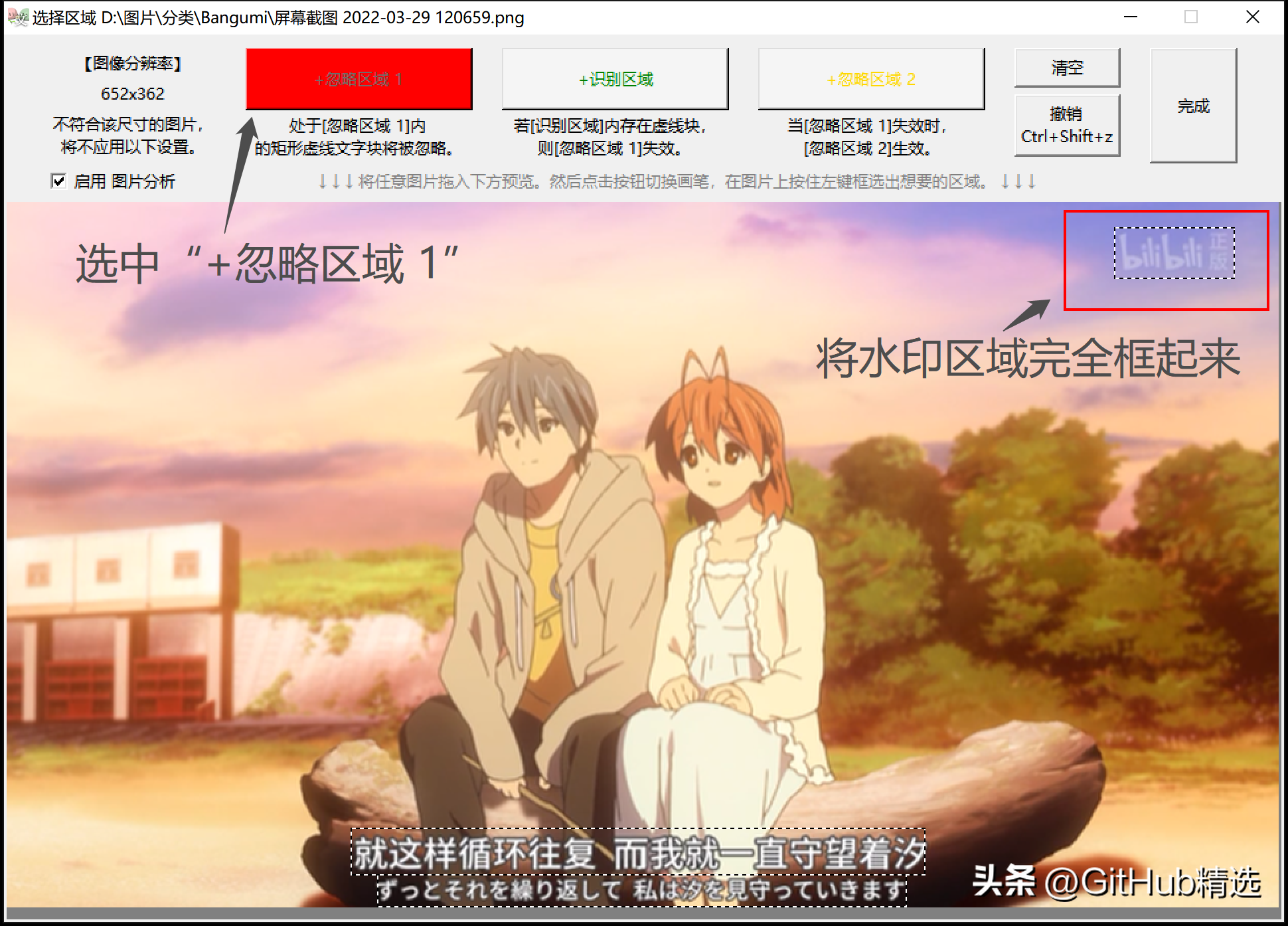
Exclude the two UIs in game screenshots
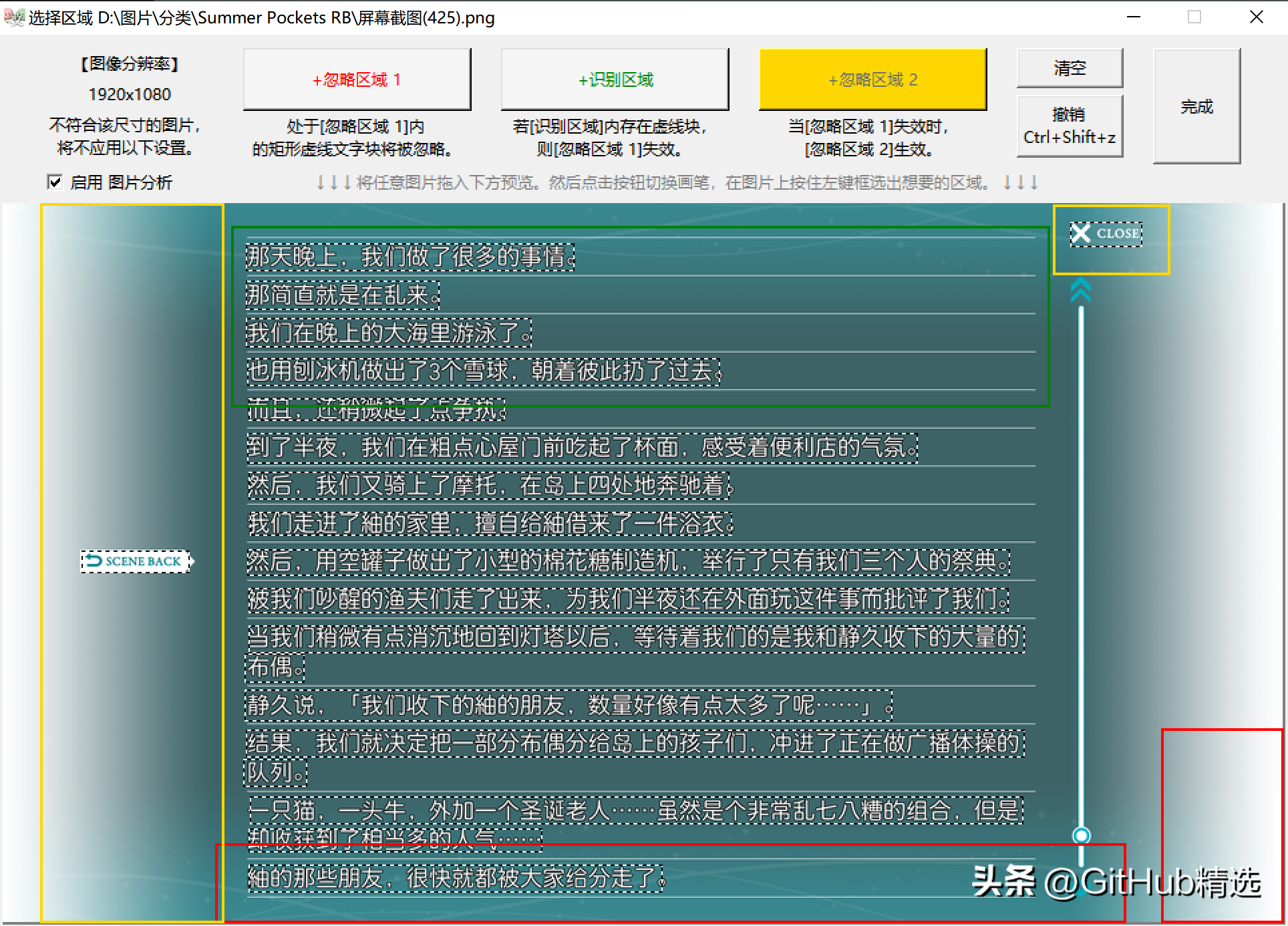
Download & Instructions
Download
https://github.com/hiroi-sora/Umi-OCR/releases/tag/v1.3.0Instructions
https://github.com/hiroi-sora/Umi-OCR#%E7%AE%80%E5%8D%95%E4%B8%8A%E6%89%8B -END-
Open source license: MIT
Open source address: https://github.com/hiroi-sora/Umi-OCR
Articles are uploaded by users and are for non-commercial browsing only. Posted by: Lomu, please indicate the source: https://www.daogebangong.com/en/articles/detail/Completely%20offline%20OCR%20imagetotext%20recognition%20tool%20UmiOCR.html
 支付宝扫一扫
支付宝扫一扫 
评论列表(196条)
测试