Preface
Html can set styles for text through Html tags, and let TextView display rich text information. It only supports some tags but not all of them. The specific supported tags will be announced in the analysis.
@Overrideprotected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); TextView textView = (TextView) findViewById(R. id.tv_html); String htmlString = '<font color='#ff0000'>Color</ font><br/>' + '<a >Link</a>< >br/>' + '<big>big font</big><br/>/>'+ '<small>small font </small><br/>'+ '<b>Bold</b><br/>'+ '< ;i>Italic </i><br/>' + '<h1>Title 1 </h1>' + '<h2>Header 2</ h2>' + '<img src='ic_launcher'/>' + '<blockquote>quote</blockquote>' + '<div>block< span class='hljs-tag' ></div>' + '<u>underscore</u> <br/>' + '<sup >superscript</sup>normal font<sub>subscript</sub><br/>' + ' <u><b>< font color='@holo_blue_light'><sup><sup>group</sup></sup>< ;big> style </big><sub>word<sub >body</sub></sub></font></b> ;</u>'; textView.setText(Html.fromHtml(htmlString));}
It can be seen that Html is still a relatively powerful thing!
Using the Html.toHtml method can generate a corresponding Html format for a Spanned text object with a style effect, and the characters in the tag will be translated into , the following is the WebView display effect, some of the effects are different from the above TextView display effect, the code is as follows:
webView.loadData(Html.toHtml(Html.fromHtml(htmlString)),'text/html' , 'utf-8');
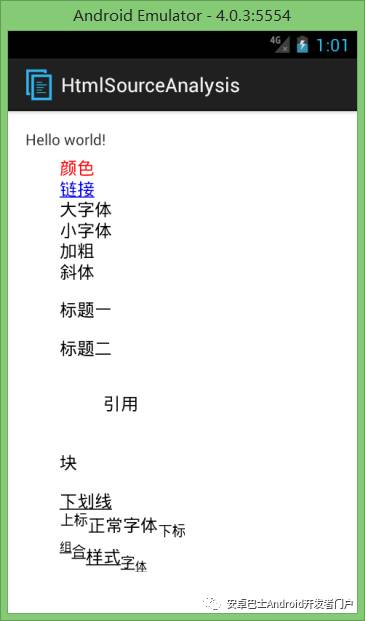
The display effect is still a bit different. I use the Android 4.0.3 mobile phone system, so there may be some problems with the display, but it should not affect everyone's distinction. After all, the point is not here, let’s continue to look at the principle!
Principle Analysis
/** * Provide image retrieval function for <img> tags*/
public static interface< /span> ImageGetter {
/** * When the HTML parser parses to <img> When labeling, the source parameter is the attribute value of src in the label, * The return value must be Drawable; if it returns null, it will be displayed with a small square, as seen above, * And the Drawable.setBounds() method needs to be called to set the size , otherwise the image cannot be displayed. * @param source: */ public Drawable getDrawable(String source);}
/*** HTML tag parsing extension interface*/
public static interface TagHandler < /span>{
/** * This method will be called when the parser parses a tag that it does not support or user-defined * @param opening: whether the tag is open * @param tag: tag name * @param output: As of the current tag, the parsed text content * @param xmlReader: parser object */ public void handleTag(boolean opening, String tag, Editable output, XMLReader xmlReader);}
private Html() { }
/** * Return styled text, all <img> tags will be displayed as a small square * Use TagSoup library to process HTML * @param< /span> source: string with html tags*/
public static Spanned fromHtml(String source) {
return fromHtml(source, null, null);}
/*** ImageGetter can be passed in to get the image source, and TagHandler can be added to support other tags*/
< /span>public static Spanned fromHtml(String source, ImageGetter imageGetter, TagHandler tagHandler) { .... .}
/*** Reversely parse the styled text into a string with Html, note that this method does not restore the text with Html tags received fromHtml*/< br>public static String toHtml(Spanned text) { StringBuilder out = new StringBuilder(); withinHtml(out, text);
return out.toString();}
/*** Return the string after translating tags*/
public static String escapeHtml(CharSequence text) { StringBuilder out = new StringBuilder(); withinStyle(out, text, 0, text.length());
return out.toString();}
/*** Lazy loading HTML parser Holder* a) zygote preloads it* b) does not load until needed*/private static class HtmlParser {
private static < span class='hljs-keyword' >final HTMLSchema schema = new HTMLSchema();}. . . .
fromHtml(String source, ImageGetter imageGetter,TagHandler tagHandler):
There are only 4 main methods of the Html class, and the functions are also simple. The generated fromHtml method with style is ultimately called a method that overloads 3 parameters.
public static Spanned fromHtml(String source, ImageGetter imageGetter, TagHandler tagHandler) {
//Initialize parser Parser parser = new Parser();
try {
//configure parsing Html mode parser.setProperty(Parser.schemaProperty, HtmlParser.schema); } catch (org.xml.sax.SAXNotRecognizedException e) {
throw new RuntimeException(e); } catch (org.xml.sax.SAXNotSupportedException e) {
throw new RuntimeException(e); } //Initialize the real parser HtmlToSpannedConverter converter =
new HtmlToSpannedConverter(source, imageGetter, tagHandler,parser);
return converter.convert();}
The source code does not contain the Parser object, but must import org.ccil.cowan.tagsoup.Parser, the HTML parser is Use the Tagsoup library to parse HTML tags. Tagsoup is a SAX-compatible parser. We know that the common parsing method for XML is DOM. Android systems also use PULL parsing and SAX are also based on the event-driven model. Tagsoup is used because the Libraries can convert HTML to XML. We all know that sometimes HTML tags do not need to be closed like XML. For example, it is also a valid tag, but it is ill-formed in XML. Details can be found on the official website, but it seems that there is no development document, so I won’t go into details here, and only focus on the SAX parsing process.
HtmlToSpannedConverter principle
class HtmlToSpannedConverter implements ContentHandler {
private static final float[] HEADER_SIZES = {
1.5f , 1.4f, 1.3f, 1.2f, 1.1f, 1f, }; private span> String mSource;
private XMLReader mReader;
private SpannableStringBuilder mSpannableStringBuilder;
private Html.ImageGetter mImageGetter;
private Html.TagHandler mTagHandler; public HtmlToSpannedConverter( String source, Html.ImageGetter imageGetter, Html.TagHandler tagHandler, Parser parser) { mSource = source;//html text mSpannableStringBuilder = new SpannableStringBuilder();//used to store strings in tags mImageGetter = imageGetter; //Image loader mTagHandler = tagHandler;//custom tagger mReader = parser;//analysis } public Spanned convert() { //Set content handler mReader.setContentHandler(this);
try { //Start parsing mReader.parse( new InputSource(new StringReader(mSource))); } catch (IOException e) { // We are reading from a string. There should not be IO problems. throw new RuntimeException(e); } catch (SAXException e) { br> // TagSoup doesn't throw parse exceptions. throw new RuntimeException(e); }
//omitted ... ... ...
return mSpannableStringBuilder;}
Through the above code, it can be found that SpannableStringBuilder is used to store and parse strings in HTML tags, Like StringBuilder, but with styled strings attached. Focus on the setContentHandler method in convert. This method receives the ContentHandler interface. Readers who have used SAX analysis should be familiar with it. This interface defines a series of methods for SAX analysis events.
public interface ContentHandler{
//Set document locator public void setDocumentLocator< /span> (Locator locator);
//Document start parsing event < span class='hljs-function' >public void startDocument () throws SAXException;
//Document end parsing event public void endDocument() throws SAXException;
//Resolve to namespace prefix event public void startPrefixMapping (String prefix, String uri) throws SAXException;
//end namespace event public void endPrefixMapping (String prefix) throws SAXException;
//Parse to tag event public void startElement (String uri, String localName, String qName, Attributes atts) throws SAXException;
//Tag end event public void endElement (String uri, String localName, String qName) throws SAXException;
// Content event in label public void characters (char ch[] , int start, int length) throws SAXException;
//ignorable space event public void ignorableWhitespace ( char ch[], int start, int length) throws SAXException;
//Process instruction event public void processingInstruction (String target, String data) throws SAXException;
//Ignore tag events public void skippedEntity (String name) throws SAXException;}
Corresponds to the implementation in HtmlToSpannedConverter.
public void setDocumentLocator(Locator locator) {}
public void startDocument() throws SAXException {}
public void endDocument() throws SAXException {}
< span class='hljs-keyword' >public void startPrefixMapping(String prefix, String uri) throws SAXException {}
public void endPrefixMapping(String prefix) throws SAXException {}
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { handleStartTag(localName, attributes);}< br>public void endElement(String uri, String localName, String qName) throws SAXException { handleEndTag(localName);}
public void characters(char ch[], int start, int length) throws SAXException { //ignore ...}
public void ignorableWhitespace(char ch[], int start, int length) throws SAXException {}
public void processingInstruction(String target, String data)< /span> throws SAXException {}
public< /span> void skippedEntity(String name) throws SAXException {}
We found that only startElement, endElement, The three methods of characters, so only care about the type of the label and the characters in the label. Then call the mReader.parse method to start parsing the HTML. The parsed event flow is as follows: startElement -> characters -> endElement The handleStartTag method is called in startElement, and the handleEndTag method is called in endElement. Space is limited, handleStartTag method analysis can click "Read the original text" to view.
From the handleStartTag method, we can summarize the list of supported HTML tags:
br
p
div
strong
b
em
cite
dfn
i
big
small
font
blockquote
tt
monospace
a
u
sup
sub
h1-h6
img
How tags are handled
br tag
Here is an analysis of how to deal with tags. In the handleStartTag method, it can be found that the br tag is directly ignored, and it is actually processed in the handleEndTag method.
private void handleEndTag(String tag) { ...
< span class='hljs-keyword' >if (tag.equalsIgnoreCase('br')) { handleBr(mSpannableStringBuilder); } ...}< br>//The code is very simple, add a line break directly
private static void handleBr< span class='hljs-params' >(SpannableStringBuilder text) { text.append('');}< /code>p tag
The p tag is a paragraph, and its function is to wrap the text in the p tag before and after. When handleStartTag and handleEndTag encounter the p tag, the handleP method is called, and the characters add the string between the p tags.
private void handleStartTag(String tag, Attributes attributes) { ... < br> else if (tag.equalsIgnoreCase('p' )) { handleP(mSpannableStringBuilder); } ...}private void handleEndTag(String tag) { ...
else if (tag.equalsIgnoreCase('p'< /span>)) { handleP(mSpannableStringBuilder); } ...}private static void handleP(SpannableStringBuilder text) {
int len = text.length(); if (len >= 1 && text.charAt(len - 1) == '') {
if (len >= 2 && text.charAt(len - 2) == '') { //If the first two characters are newlines, then ignore return; }
//otherwise add a line break text.append('');
return; }
//Add two newlines in other cases if ( len != 0) { text.append(''); }}stronglabel
The function of this tag is to bold the font, and the start and end methods are called in handleStartTag and handleEndTag respectively.
private void handleStartTag(String tag, Attributes attributes) { ... < br> else if (tag.equalsIgnoreCase('strong' )) { start(mSpannableStringBuilder, new Bold()); } ...}private static class Bold { }//Nothing
private void handleEndTag(String tag) { ...
else if (tag.equalsIgnoreCase('strong')) { end(mSpannableStringBuilder, Bold.class, new StyleSpan (Typeface.BOLD)); } ...}
private static void start(SpannableStringBuilder text, Object mark) {
int len = text.length();
//mark has no actual function as a type mark, indicating the start position, //The end position is delayed to the `end` method, //Spannable.SPAN_MARK_MARK means that when text is inserted offset, they remain at their original offset. Conceptually, the text is added after the markup. text.setSpan(mark, len, len, Spannable.SPAN_MARK_MARK); } private static void end (SpannableStringBuilder text, Class kind, Object repl) {
//Current character length int len = text.length();
//Get the last set object according to kind Object obj = getLast(text, kind );
//Get the label start position int where = text.getSpanStart(obj);
//Remove tag object text.removeSpan(obj); if (where != len) {
//len is the end position, Spannable.SPAN_EXCLUSIVE_EXCLUSIVE is to set the style text interval as a closed interval // Set the real style object repl, Bold corresponds to StyleSpan type, Typeface.BOLD bold style text.setSpan(repl, where, len, Spannable.SPAN_EXCLUSIVE_EXCLUSIVE); }}
private static Object getLast (Spanned text, Class kind) {
/* * Get the last type as king, in The object passed in by setSpan * For example, if the kind type is Bold.class, the Bold object set in start will be returned */ Object[] objs = text.getSpans( 0, text.length(), kind); if (objs.length == 0) {
return null; } else< /span> {
//If there are multiple periods, get the last one return objs [objs.length - 1]; }}After the start and end methods are processed, the strong tag The text will be bolded, and the specific style type will not be explained in detail here. Follow-up, you can refer to Spannable source code analysis, which is currently unclaimed article. The process of setting different styles for other fonts is the same. When handleStartTag calls start according to different tag types The method passes in different objects to mark, and calls end for different tags in handleEndTag and passes in different styles.
font tag
The font tag can specify the color and font for the string.
private void handleStartTag(String tag, Attributes attributes) { ... < br> else if (tag.equalsIgnoreCase('font' )) {
//attributes with attributes in the tag //for example <font color ='#FFFFFF'>, the attribute will exist in the form of key-value, {'color':'#FFFFFF'}. startFont(mSpannableStringBuilder, attributes); } ...}
private static void startFont( SpannableStringBuilder text,Attributes attributes) { String color = attributes.getValue('', ' color');//Get color attribute String face = attributes.getValue('' , 'face');//Get face attribute int len = text.length();
//Font is also an object used to mark attributes, and has no actual function text.setSpan(< span class='hljs-keyword' >new Font(color, face), len, len, Spannable.SPAN_MARK_MARK);}
//save color value and Font typeprivate static class Font {
public String mColor;
public String mFace;
public Font(String color, String face) { mColor = color; mFace = face; }}
private void handleEndTag(String tag) { ...
else if (tag. equalsIgnoreCase('font')) { endFont(mSpannableStringBuilder); } ...}
private static void endFont(SpannableStringBuilder text) {
int len = text.length(); Object obj = getLast(text, Font.class);
int where = text.getSpanStart(obj); text.removeSpan(obj);
if (where != len) { Font f = (Font) obj;
//The front is similar to the strong tag parsing process, with the following logic for processing colors and fonts if (!TextUtils.isEmpty(f.mColor)) {
//If the color attribute starts with '@', get the color corresponding to the colorId Value //Note: only support android.R resources if (f.mColor .startsWith('@')) { Resources res = Resources.getSystem(); String name = f.mColor.substring(1);
int colorRes = res.getIdentifier(name, 'color', 'android');
if (colorRes != 0) { //It can also be a color selector, which will display different colors according to different states ColorStateList colors = res. getColorStateList( colorRes, null);
text.setSpan(new TextAppearanceSpan(null, 0, 0, colors, null), Spannable.SPAN_EXCLUSIVE_EXCLUS IVE);} } else {
//If it starts with '#', parse the color value int c = Color.getHtmlColor(f.mColor);
if (c != -1) {
//2. Directly set the rgb value of the font through ForegroundColorSpan text.setSpan(< span class= 'hljs-keyword' >new ForegroundColorSpan(c | 0xFF000000), where, len, Spannable. SPAN_EXCLUSIVE_EXCLUSIVE); } } }
if (f.mFace != null) {
// If there is a face parameter, set the font through TypefaceSpan text.setSpan(new TypefaceSpan(f.mFace), where, len, Spannable.SPAN_EXCLUSIVE_EXCLUSIVE);private static void apply(Paint paint, String family) { ...
//Analysis font Typeface tf = Typeface.create(family, oldStyle); ... }
Typeface source code is as follows:
/*** Get the font object according to the font name, if the familyName is null, return the default font object* Call getStyle to View the font style attribute** @param font name, may be null* @param style NORMAL (standard ), BOLD (bold), ITALIC (italic), BOLD_ITALIC (bold italic)* @return matching font*/public static Typeface create (String familyName, int style) {
if (sSystemFontMap != null) {
//The font is cached in sSystemFontMap< /span> return create(sSystemFontMap.get(familyName), style); }
return < span class='hljs-keyword' >null;} //init method initializes sSystemFontMap private static void init() {
// Get font configuration file directory //private static File getSystemFontConfigLocation() { //return new File('/system/etc/'); //} File systemFontConfigLocation = getSystemFontConfigLocation();
//Get font configuration file //static final String FONTS_CONFIG = 'fonts.xml'; File configFilename = new File(systemFontConfigLocation, FONTS_CONFIG);
try { //Cache font name and Typeface object in map class='hljs-comment' >//The specific parsing process is ignored, if you are interested, you can read the source code by yourself ... ... sSystemFontMap = systemFonts; } catch ( RuntimeException e) { ... }}
img tag
//img tags are only processed at the beginning of the tag
private void handleStartTag(String tag, Attributes attributes) {
...
else if (tag.equalsIgnoreCase('img')) { startImg(mSpannableStringBuilder, attributes, mImageGetter); } ...
}
//Processing with other tags has more Attributes tag attributes, Html.ImageGetter custom image acquisition
private static void startImg(SpannableStringBuilder text, Attributes attributes, Html .ImageGetter img) {
//Get src attribute String src = attributes.getValue('', 'src'); Drawable d = null; if (img != null) {
//Called from Define the image acquisition method and pass in the src attribute value d = img.getDrawable(src); } if (d == null) {
//If the image is empty, return a small box d = Resources.getSystem(). getDrawable (com.android.internal.R.drawable.unknown_image); d.setBounds(0, 0, d.getIntrinsicWidth(), d.getIntrinsicHeight()); } int len = text.length();
//Add picture placeholder characters text.append('uFFFC');
//Pass Use ImageSpan to set picture effect text.setSpan(new ImageSpan(d, src), len, text.length(), Spannable.SPAN_EXCLUSIVE_EXCLUSIVE);}< /span>
Custom Labels
private void handleStartTag(String tag, Attributes attributes) { ... < br> else if (mTagHandler != null) {
//Extend custom tags through custom tag handlers mTagHandler.handleTag(true span>, tag, mSpannableStringBuilder, mReader); } ...}
private void handleEndTag(String tag) { ... < br> else if (mTagHandler != null) {
//close tag mTagHandler.handleTag(false, tag, mSpannableStringBuilder, mReader) ; } ...}
There is a small problem with custom tags. The handleTag does not pass in the Attributes tag attribute, so the attribute value of the custom tag cannot be obtained directly. Two solutions are given below to solve this problem:
1. Use a certain part of the tag name as the attribute value, such as the <custom> tag, if we want to add the id parameter, we can change the tag name to <custom-id-123>, and then parse it in handleTag .
2. Obtain attribute values by reflecting XMLReader. For specific examples, please refer to stackoverflow:How to get an attribute from an XMLReader
The remainder of the convert method
Don't ignore the part of the code after parse.
//Correction of paragraph mark range
//ParagraphStyle is paragraph level style
Object[] obj = mSpannableStringBuilder.getSpans(0, mSpannableStringBuilder.length(), ParagraphStyle.class);
for (int i = 0; i < obj.length; i++) {
int start = mSpannableStringBuilder.getSpanStart(obj[i]);
int end = mSpannableStringBuilder.getSpanEnd(obj[i]); // remove the last two newlines if (end - 2 >= 0) {
if (mSpannableStringBuilder.charAt(end - 1) == '' && mSpannableStringBuilder. charAt(end - 2) == '') { end--; } } }
< span class='hljs-keyword' >if (end == start) {
//Remove styles that are not displayed mSpannableStringBuilder.removeSpan(obj [i]); } else {
//Spannable.SPAN_PARAGRAPH starts and ends with line break span> mSpannableStringBuilder.setSpan(obj[i], start, end, Spannable.SPAN_PARAGRAPH); }}
return mSpannableStringBuilder;
Space is limited, please click "Read the original text" in the lower left corner to view the full content.
Everyone is watching So many high-quality foreign programmer websites have been sorted out for you, don’t just look at them in a daze!
Using Kotlin to develop Android projects - Kibo (2)
223 commonly used custom views and third-party libraries
The secret of View unit conversion [system source code analysis]
Welcome to the Android Bus ForumBowenZonePublish blog posts, excellent articles we will Make multi-channel recommendations. For details, see "As an Excellent Programmer, Are You Really Qualified?" "
Click "read the original text" View All
Articles are uploaded by users and are for non-commercial browsing only. Posted by: Lomu, please indicate the source: https://www.daogebangong.com/en/articles/detail/Android%20rich%20text%20Html%20source%20code%20detailed%20analysis.html
 支付宝扫一扫
支付宝扫一扫 
评论列表(196条)
测试