在IJCAI2016的教程上,微软研究院分享了他们将深度学习和深度神经网络应用到不同领域的实际案例。上一篇我们提及了语义理解上的一些经验和成就,本文是第二部分。
联合编译:Blake、章敏、陈圳

统计机器翻译(SMT)包含:
l 统计结果
l 来源信道模型
l 翻译模型
l 语言模型
l 对数线性模型
l 评价标准:BLEU分数(越高越好)

基于短语的统计机器翻译(SMT),用于将中文翻译成英文

核心问题:应该针对什么进行建模?
l 针对词汇可能性
语言模型
LM/w 来源
l 基于短语的机器翻译 翻译/录制的可能性
翻译
录制
l 基于二元的机器翻译
l ITG模型

在基于短语的SMT中使用神经网络的例子
l 神经网络作为线性模型的一部分
翻译模型
预压模型 巻积神经网络的应用
联合模型 FFLM与原始词汇结合
l 神经机器翻译(NMT)
创建一个大型的神经网络来读取句子并生成翻译
RNN 编码-解码
长短时记忆
联合学习序列、翻译
NMT在WMT任务上的表现超越了最佳效果

短语翻译模型虽然结构简单,但有效应对了数据稀少的问题。

深度语义相似模型(DSSM)
l 计算文本间的语义相似度
l 适用于自然语言处理任务的DSSM

针对短语翻译模型的DSSM
l 两个神经网络(一个方向是来源,一个方向是目标)
输入
输出
l 短语翻译评分=向量点积
评分
为了缓解数据稀疏性,允许复杂的评分函数

N-gram语言模型
l 词汇n-gram模型(例如n=3)
l 长期历史的使用问题
稀少事件:不可靠的可能性预测

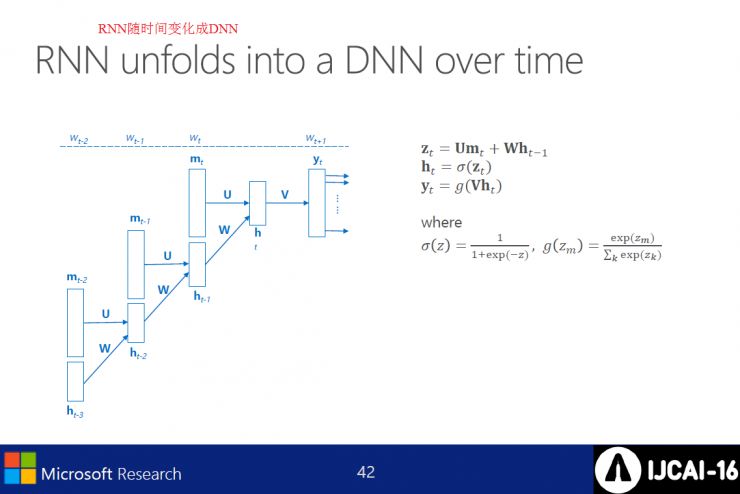

RNN LMs需要回到句子的起点,这也导致动态规划难度增加。为每一个新词汇评分时,每个解码器的状态都需要保持在h,通过结合传统的n-gram上下文和最优的h来重新组合假设。

模拟S需要三个条件:1. 全句或均衡的源词汇 2. S作为词汇序列、词袋或向量表示 3. 如何学习S的向量表示?神经网络联合模型基于递归神经网络语言模型和前馈神经网络模型。
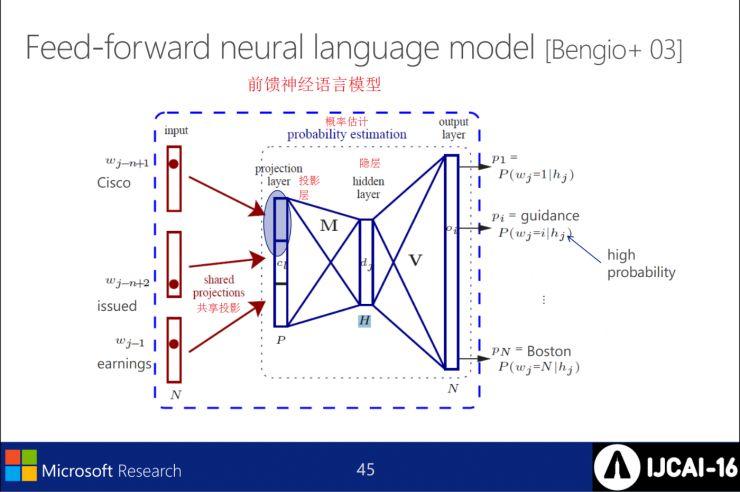
前馈神经语言模型

扩展前馈LM,使其包含周围均衡源词汇窗口。如果对齐多个源词汇,则选择中心位置;若不需对齐,则继承最近目标词汇的队列。用队列在文本中进行训练,优化对目标的预测可能性。

神经机器翻译,建立一个单独的大型神经网络,读取句子并生成翻译。不像基于短语的系统,需要很多组件模型。编码器-解码器基础方法是:编码器RNN读取并将源句子编码为固定长度向量,解码器RNN从编码器向量输出变长度翻译,最终编码器-解码器RNNs联合学习文本,优化目标可能性。

[Sutskever+2014]编码器-解码器模型
将MT看作通用的序列到序列的翻译,读取源头;累积隐状态;生成目标。其间:

潜力与挑战
从理论上讲,RNN可以将所有过去输入的信息“存储”在h中,但在实践中,标准的RNN难以捕捉长距离的依赖。解决反向传播中梯度消失、爆炸和不稳定噪音问题的方法是:长短期记忆。
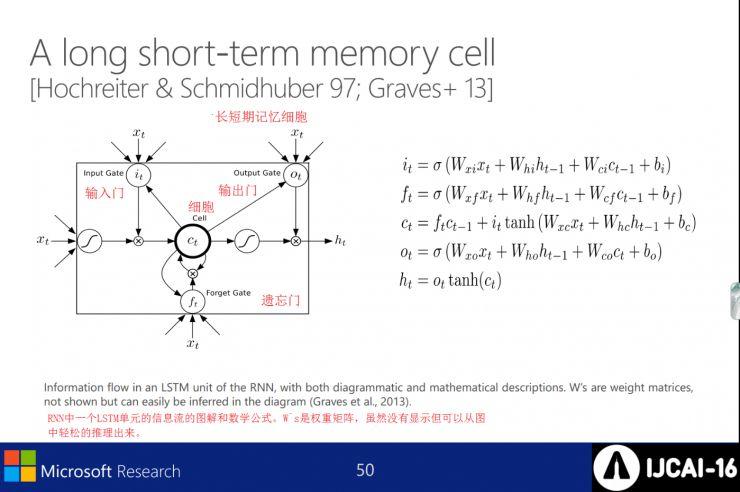
长短期记忆细胞
在RNN中,一个LSTM单元如何进行信息流处理的图示和数学公式。W`s是权重矩阵,虽然没有显示,但可以从图中轻松推理出来。

两个门的记忆细胞
图2:所提议的隐激活函数。更新门z决定是否更新隐藏状态为新的隐藏状态h。复位门r决定先前的隐藏状态是否被忽略。

对齐和翻译的联合学习
SMT的编码器-解码器模型存在一个问题:将源信息压缩到一个固定长度的向量中,使得RNN难以处理复杂长句。注意力模型解决了这个问题:将输入句子编码为向量序列,并在解码时选择向量的子集。
其想法类似于[Devlin+14]。

[Bahdanau+15]的注意力模型
编码器:双向RNN编码每个单词和句子
解码器:找到一系列与预测目标词汇最相关的源词汇,并基于源词汇和所有先前生成词汇预测目标词汇。这样,长句子翻译接近最佳性能。

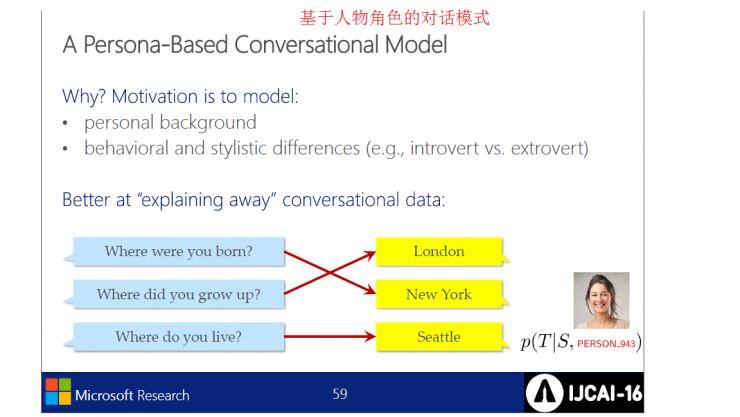
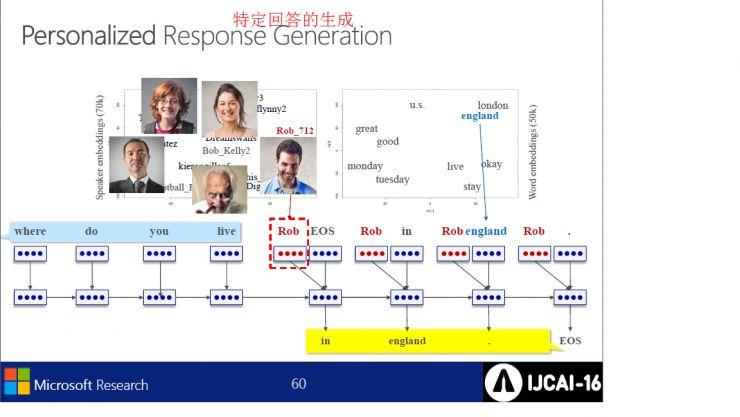
MSR的神经对话引擎




 支付宝扫一扫
支付宝扫一扫 
评论列表(196条)
测试