在有关深度学习的实际科研或工程中,经常需要在本机上复现别人的代码,而由于Python和Pytorch各个版本存在不兼容的现象,最让人头疼的就是深度学习的环境配置问题,特别是需要用到GPU进行加速时,配置好了这个,却影响了之前的工程,如何解决这一痛点问题,请阅读本教程。
相比于网络上面的其他教程,本篇教程所示方法最大的优点是在执行不同环境配置要求的工程时候,不需要重复安装/卸载电脑本机的cuda程序,可以大大节约环境配置时间,更重要的是不会因为更改显卡配置而影响其他软件或程序的正常运行。
本文最后通过深度学习入门案例手写字体识别(MNIST)的程序验证本文方法的有效性。

- Anaconda
Anaconda是一个用于科学计算和数据分析的免费开源发行版,包含了许多常用的Python数据科学库和工具,如NumPy、Pandas、Matplotlib、SciPy等。Anaconda提供了一个包管理器,允许用户轻松地安装、更新和删除包。使用Anaconda配置环境相对于直接配置环境有以下优势:
- 方便管理依赖项:Anaconda自带的包管理器Conda可以方便地安装和管理Python包及其依赖项,避免了手动安装依赖项的繁琐过程。同时,使用Conda,可以轻松地创建和删除虚拟环境,避免了环境污染和版本冲突的问题。
- 包含常用的数据分析和科学计算工具:Anaconda默认安装了许多数据分析和科学计算库,如NumPy、Pandas、Matplotlib、SciPy等。这些库是数据分析和科学计算中经常使用的工具,使用Anaconda可以避免手动安装这些库和依赖项的繁琐过程。
- 跨平台支持:Anaconda可以在Windows、Linux和MacOS等多个操作系统上运行,因此可以在不同的开发环境中共享相同的Python代码和依赖项,避免了因为不同操作系统导致的兼容性问题。
相比之下,直接配置环境需要手动安装依赖项和环境配置,操作相对繁琐,同时也容易出现版本冲突和环境污染等问题。因此,使用Anaconda配置环境可以更方便、更快速地完成环境配置,提高了开发效率和代码可维护性。
- Pytorch
PyTorch是一个由Facebook开发的基于Python的开源机器学习框架,主要用于构建神经网络和深度学习模型。PyTorch提供了一个灵活的张量计算库,可以在GPU和CPU上进行高效的数值计算,并支持自动求导和动态计算图。PyTorch在深度学习领域得到了广泛应用,被用于图像分类、目标检测、语音识别、自然语言处理等多个领域。同时,PyTorch也被用于研究领域,许多最新的研究成果都是基于PyTorch实现的。
- Anaconda3的安装:较为容易,可参考网上其他教程。
- 基于Anaconda3的环境配置
1、选择以管理员身份运行Anaconda Prompt
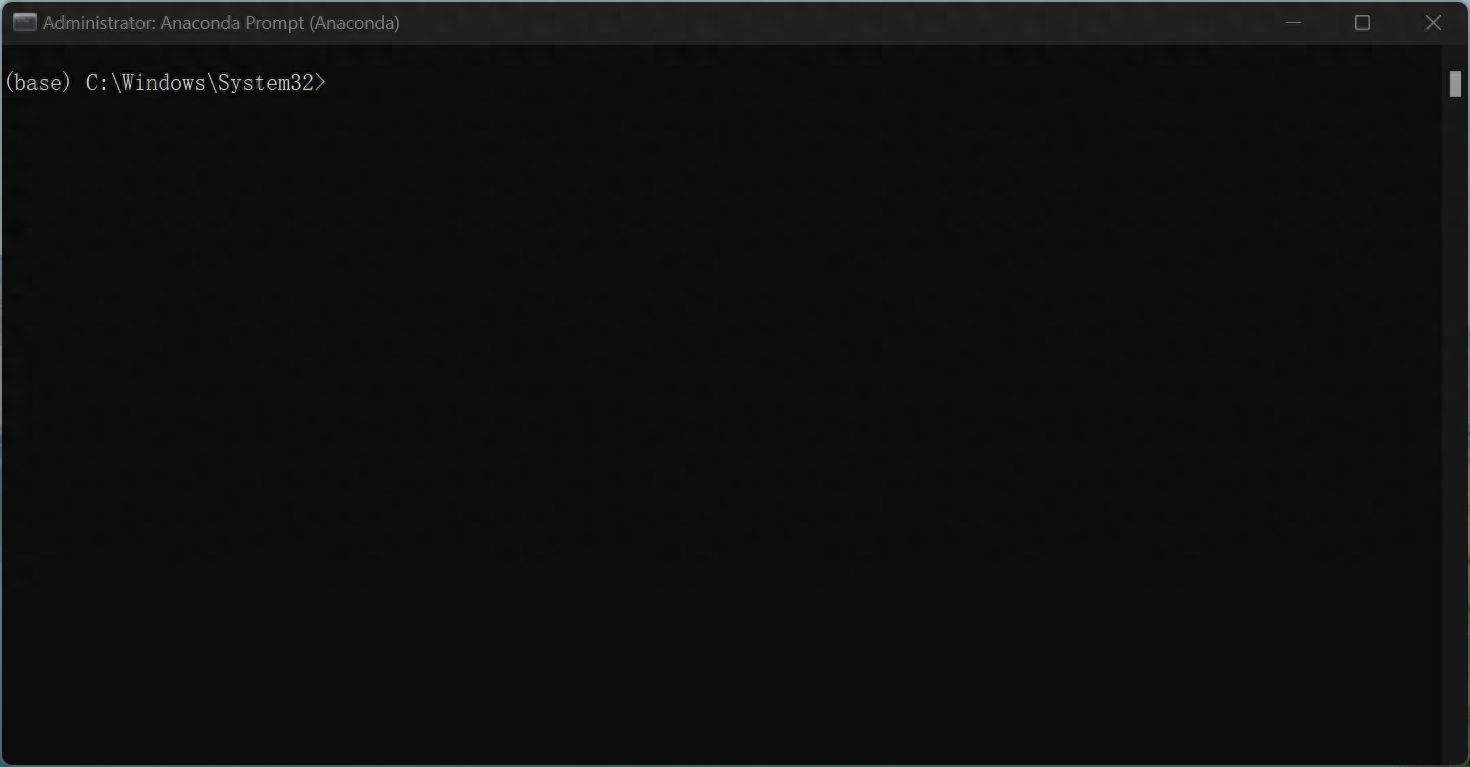
打开后命令行的最前方为(base),"base"是指默认创建的Python环境,当使用Anaconda创建新的Python环境时,可以选择在"base"环境的基础上创建新的环境,或者从零开始创建新的环境。新创建的环境将不会包含"base"环境中的默认包和工具,但是可以通过安装新的包和工具来扩展该环境的功能。写本文的目的在于让各类python工程之间不互相影响,因此尽量不要在base环境下做任何更改性的操作!
2、接下来考虑自己要创建什么样的环境,本文以创建使用python3.6.2的pytorch为1.7的环境作为示例。(这里python的版本和pytorch版本,以及后续cudatoolkit版本需对应好)
输入 :
conda create --name pytorch17 python==3.6.2这句代码的意识是创建一个名字为“pytorch17”的环境,用的是python=3.6.2
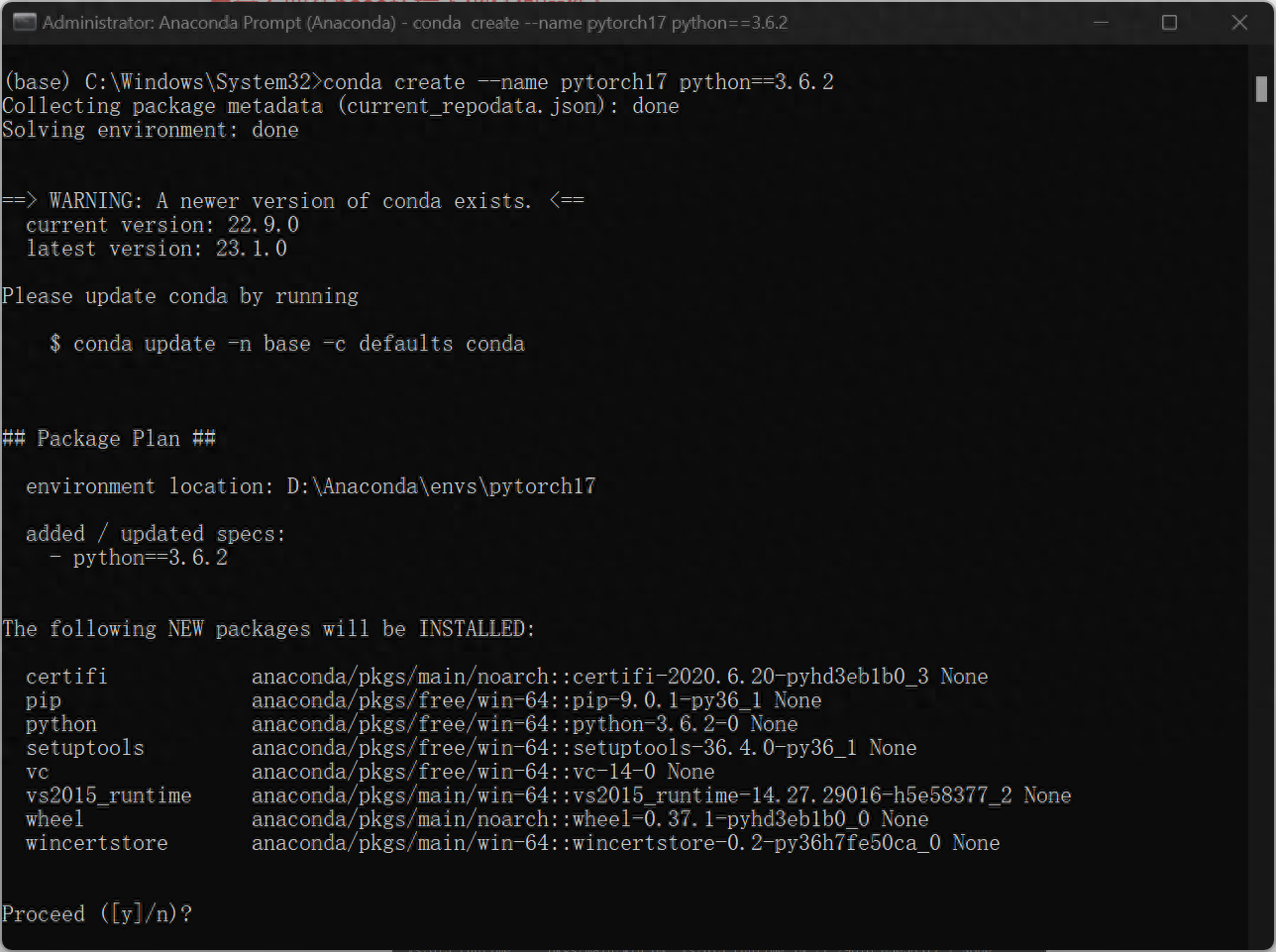
确认安装,输入y
然后进行下载安装
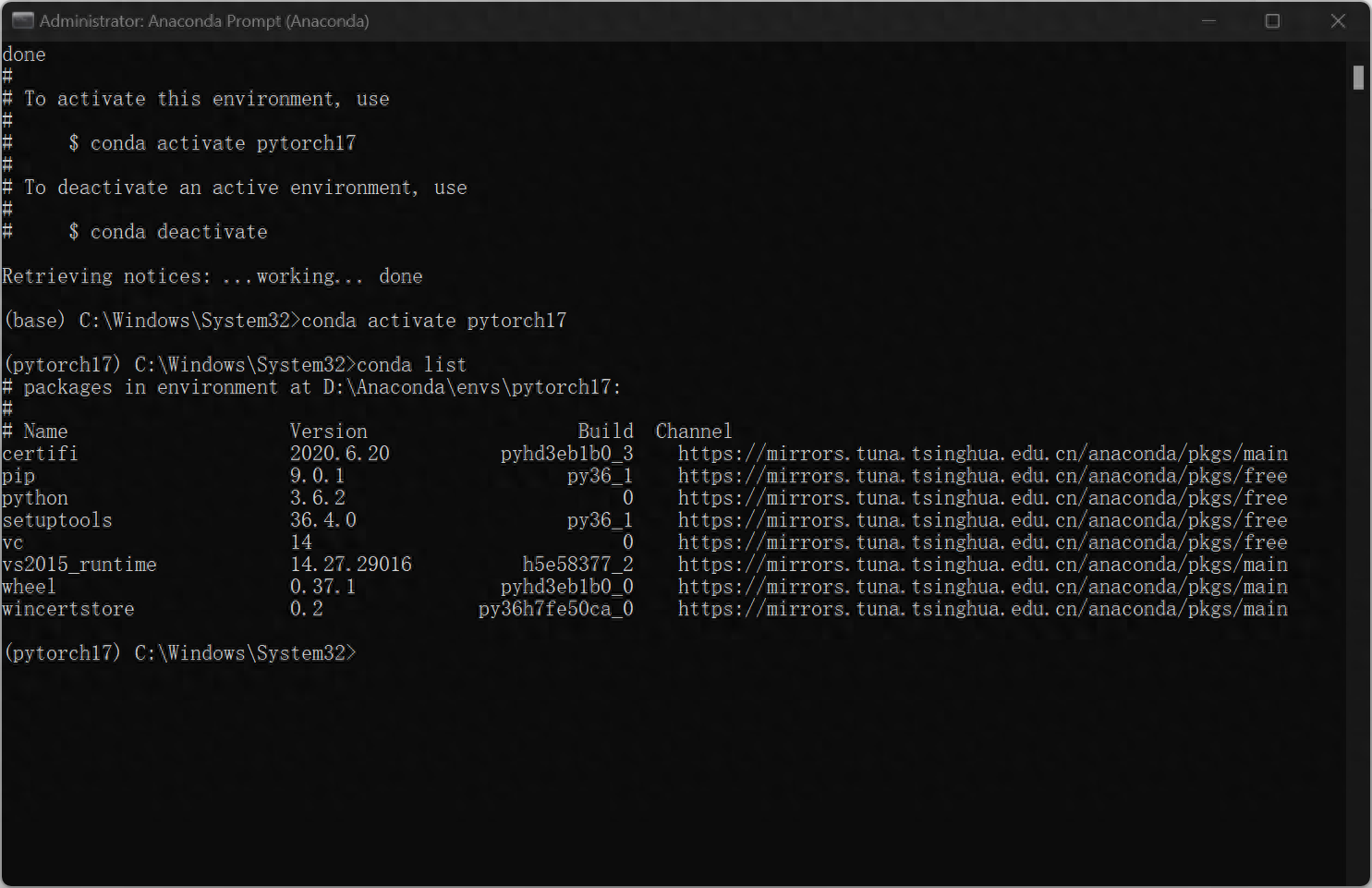
安装完毕后输入
conda activate pytorch17即进入刚刚创建的pytorch17环境中,此时发现命令行前面变为(pytorch17),接着键入:conda list,展示pytorch所安装的python包,至此环境已创建完毕。
3、接下来配置Pytorch-GPU,示例中作者想要创建的pytorch版本是1.7.0,cuda版本是11.0
输入:
conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=11.0 -c pytorch若想安装不同版本的pytorch和cuda,可查询网站:https://pytorch.org/get-started/previous-versions/
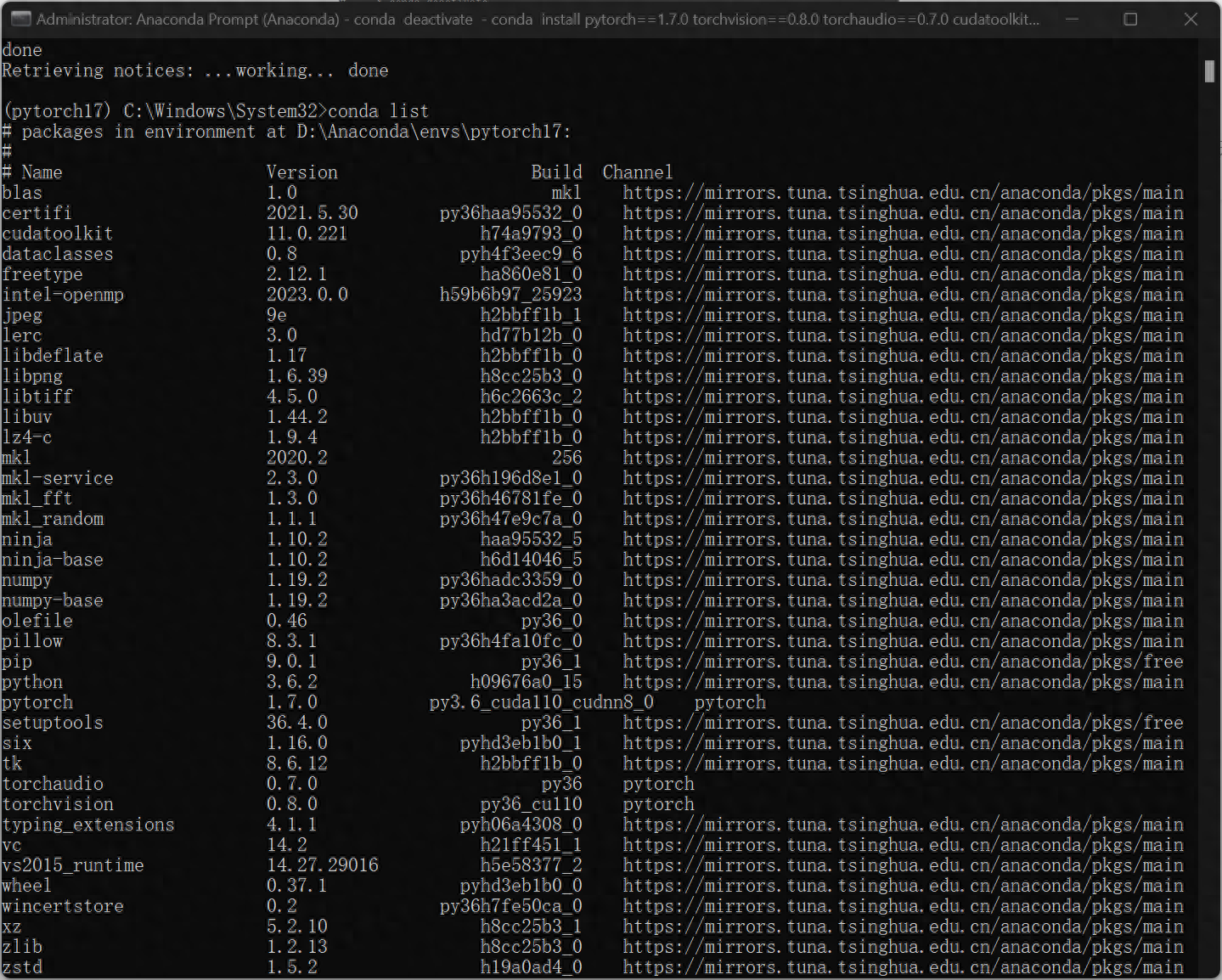
4、验证是否GPU是否工作
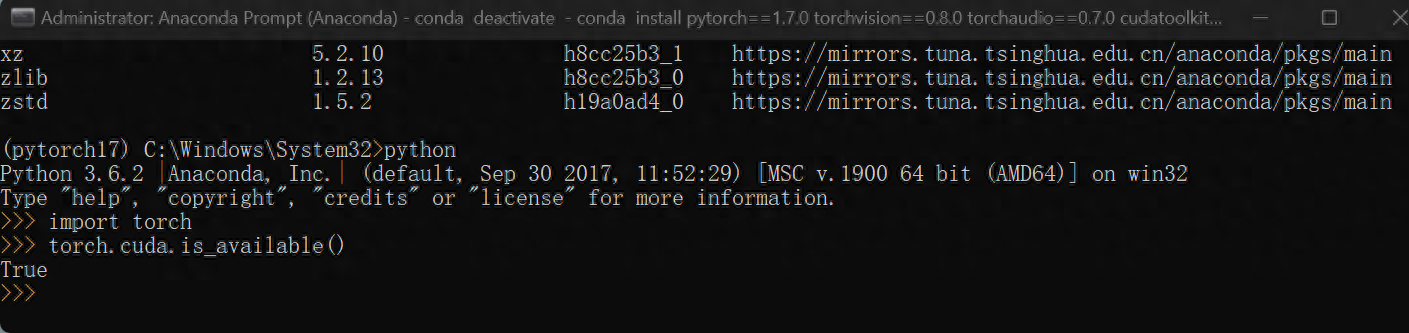
python
>>import torch
>>torch.cuda.is_available()返回True即表示GPU正常工作。
5、在pycharm中配置环境(pycharm安装过程略)
在新建工程的过程中,选择existing interpreter,再选择刚刚创立好的pytorch17,如图所示:
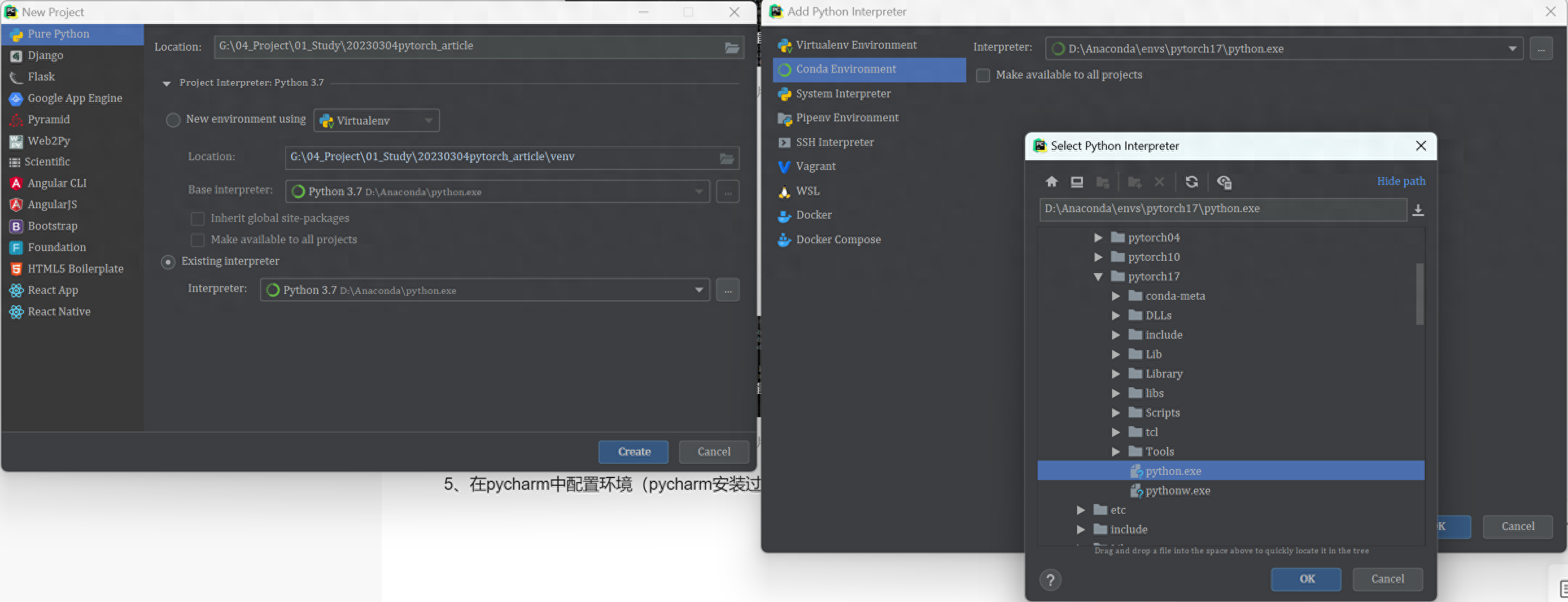
至此,可以开始编程了。
6、手写字体识别验证环境正确
创建文件:
复制此代码并执行(如需获取全部代码请关注公粽号:控我所思VS制之以衡)
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
BATCH_SIZE = 1024*50 # 每批处理的数据
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(torch.cuda.is_available())
EPOCHS = 20 # 训练数据集的轮次
pipeline = transforms.Compose([
transforms.ToTensor(), # 将图片转换成tensor
transforms.Normalize((0.1307,), (0.3081,)) # 降低模型的复杂度,正则化
])
from torch.utils.data import DataLoader
# 下载数据集
train_set = datasets.MNIST("data", train=True, download=True, transform=pipeline)
test_set = datasets.MNIST("data", train=False, download=True, transform=pipeline)
# 加载数据
train_loader = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_set, batch_size=BATCH_SIZE, shuffle=True)
# 构建网络
class Digit(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 10, 5)
self.conv2 = nn.Conv2d(10, 20, 3)
self.fc1 = nn.Linear(20 * 10 * 10, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
input_size = x.size(0)
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, 2, 2)
x = self.conv2(x)
x = F.relu(x)
x = x.view(input_size, -1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1) # 计算分类后,每个数字的概率值
return output
model = Digit().to(DEVICE)
optimizer = optim.Adam(model.parameters())
def train_model(model, device, train_loader, optimizer, epoch):
# 模型训练
model.train()
for batch_index, (data, target) in enumerate(train_loader):
# 部署到device上去
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
# 反向传播
loss.backward()
optimizer.step()
if batch_index % 3000 == 0:
print("Train Epoch : {} \t Loss : {:.6f}".format(epoch, loss.item()))
def test_model(model, device, test_loader):
model.eval()
correct = 0.0
test_loss = 0.0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.cross_entropy(output, target).item()
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print("Test Average loss : {:.4f},Accuracy : {:.3f}\n".format(test_loss,100.0 * correct / len(test_loader.dataset)))
for epoch in range(1, EPOCHS + 1):
train_model(model, DEVICE, train_loader, optimizer, epoch)
test_model(model, DEVICE, test_loader)
代码开始运行,下载MNIST手写字体识别的数据集。
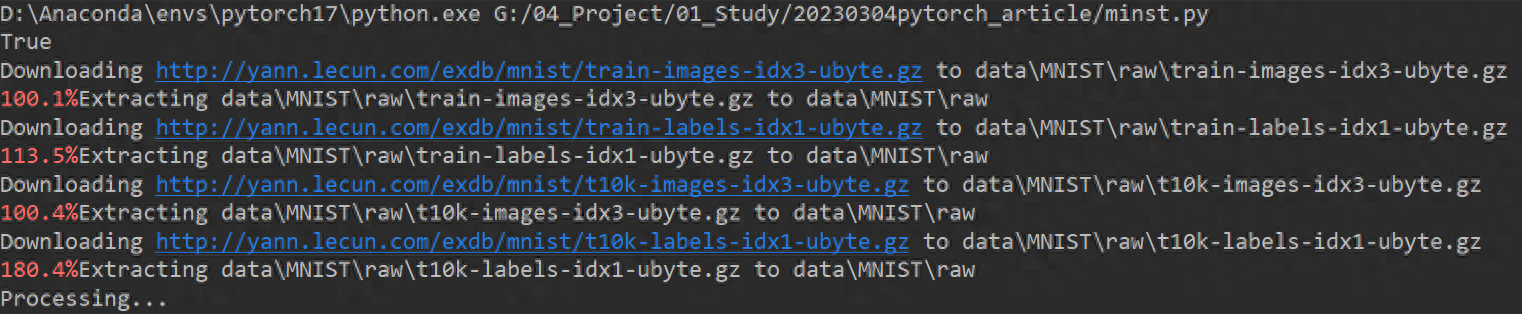
训练开始:

此时用win+R,输入cmd,再输入nvidia-smi检查显卡状况,显卡正在工作中
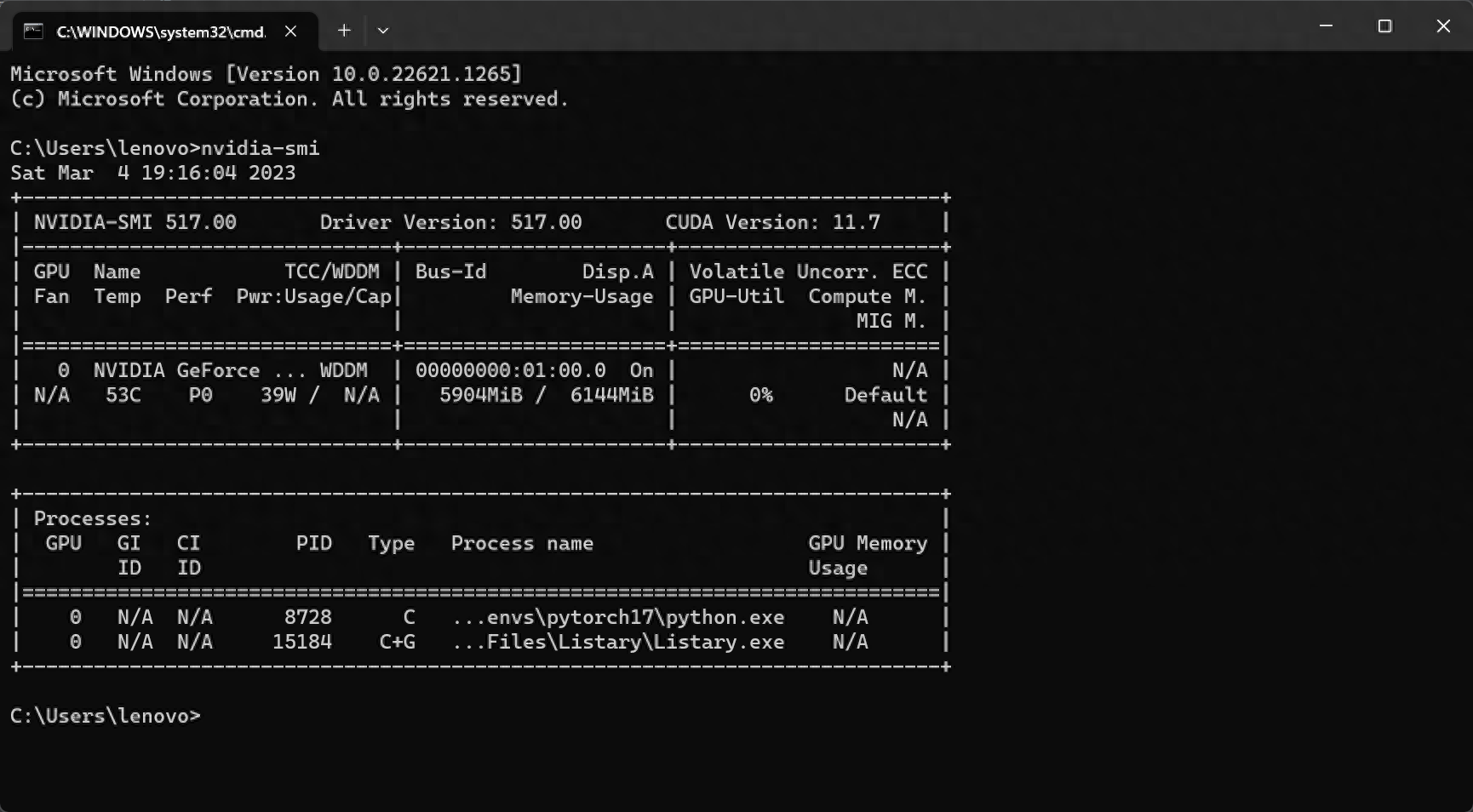
此时已经全部完成,可以专注编写代码了。
7、如果想删除配置的环境,重新打开Anaconda Prompt 输入如下代码
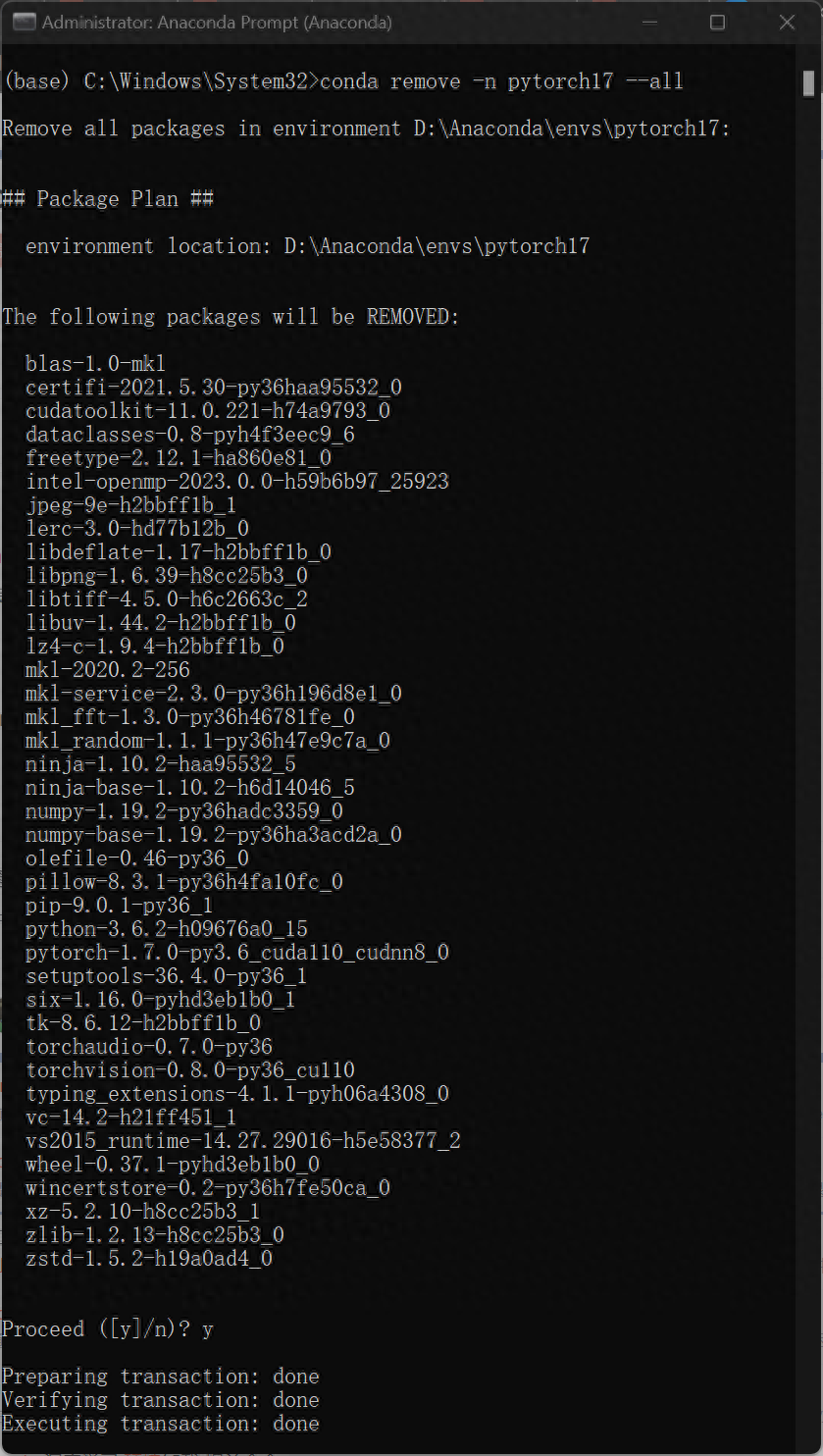
本篇教程所示方法最大的优点是在执行不同环境配置要求的工程时候,不需要重复安装/卸载电脑本机的cuda文件,可以大大节约环境配置时间,更重要的是不会因为更改显卡配置而影响其他软件或程序的正常运行。
制作不易,喜欢请点赞、留言、收藏、关注!
文章为用户上传,仅供非商业浏览。发布者:Lomu,转转请注明出处: https://www.daogebangong.com/articles/detail/pei-zhi-shen-du-xue-xi-PytorchGPU-Cuda-huan-jing-tu-wen-jiao-cheng-ji-shou-xie-zi-ti-shi-bie-yan-zheng.html
 支付宝扫一扫
支付宝扫一扫 
评论列表(196条)
测试