1、目的
将网页中的PPT的各个页面截图下载到本地。
2、调试
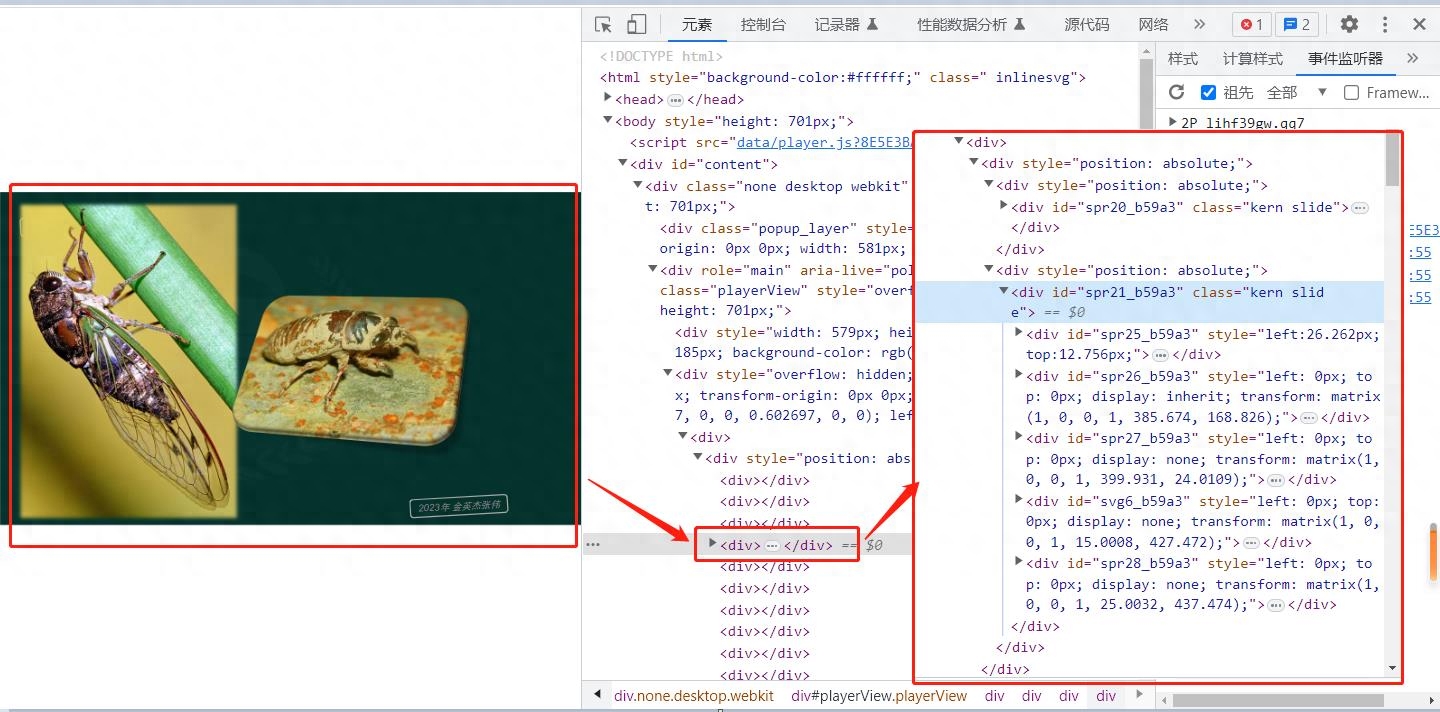
1)打开控制台查看元素,可以发现PPT的页面是用DOM元素实现的。基于这个情况,首先想到的是使用html2canvas将PPT页面截图保存到本地。
01
2)接下来要考虑的是PPT如何自动翻页。经过一番调试后,发现:
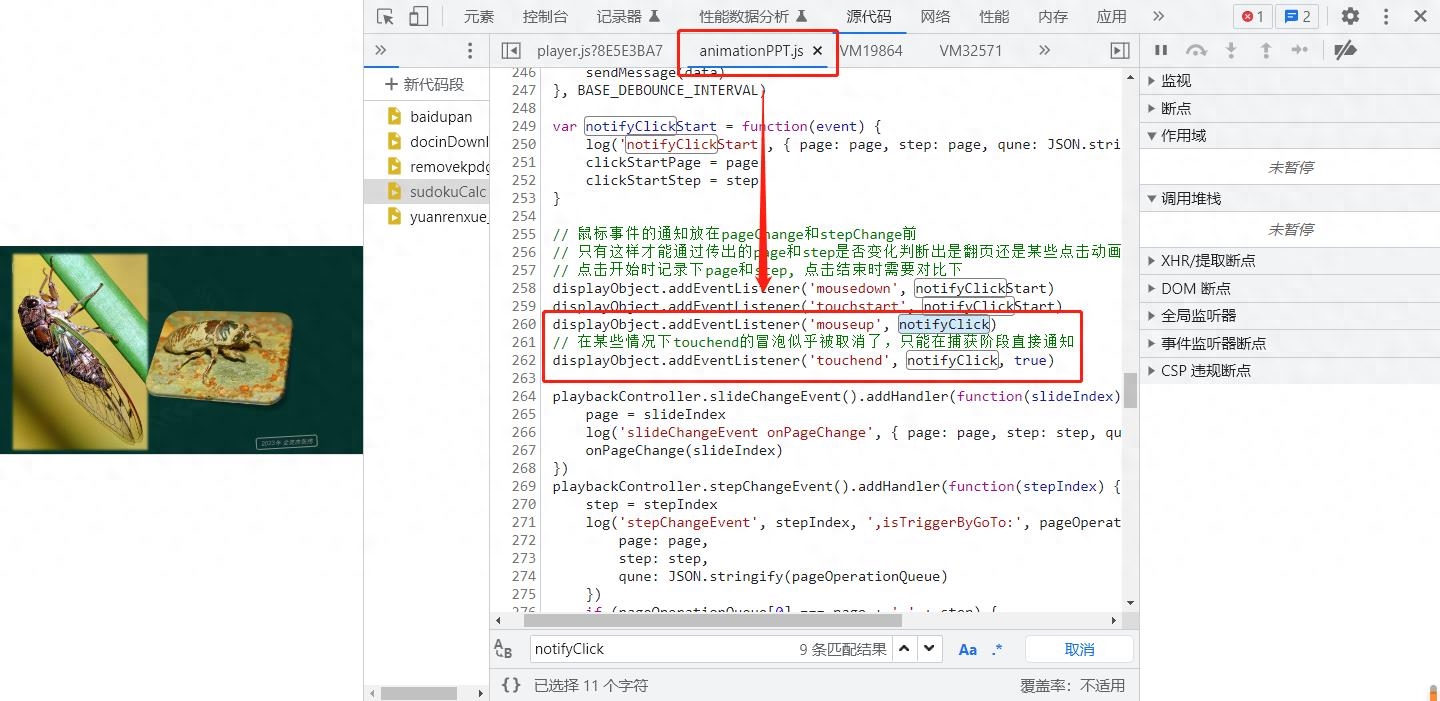
a、PPT的翻页功能是通过 mousedown 和 mouseup 事件配合实现的;
b、核心的业务逻辑放在 notifyClick 这个函数中;
02
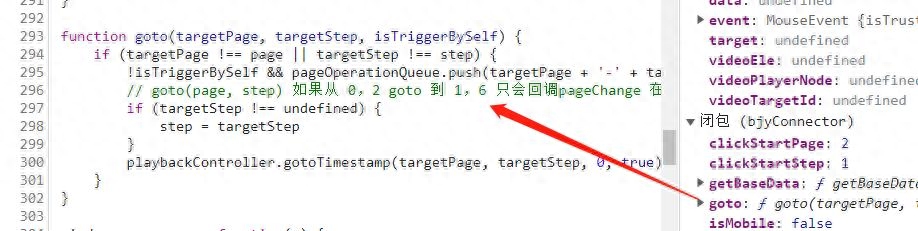
c、在 notifyClick 中打上断点,可以看到这里有一个 bjyConnector 对象,它其实就是这个PPT文档的控制器,它上面有个 goto 方法,可以用来实现翻页。

03
04
d、有了翻页控制器,接下来通常会想要知道PPT总共有多少页,否则就不知道什么时候停止“翻页+截图”。但这里,经过测试,我发现并不需要知道总页数,因为超出PPT总页数时,函数会抛出错误,我们可以利用这个错误来控制何时停止它。
3、代码编写
// 函数:加载script标签
function loadScript (url) {
let ele = document.createElement('script')
ele.src = url
document.body.appendChild(ele)
}
// 函数:用a标签下载图片
function downloadFileByA (options) {
let from = ''
let to = ''
if (typeof options === 'string') {
from = options
} else{
from = (options || {}).from
to = ((options || {}).to || '').split(/[\\|\/]/g).pop()
}
let ele = document.createElement('a')
ele.target = '_blank'
ele.download = to
ele.style.display = 'none'
ele.href = from
document.body.appendChild(ele)
ele.click()
document.body.removeChild(ele)
}
// 变量:PPT页面所在的盒子元素
let _domObj = document.querySelector('#playerView div:nth-child(2)');
// 变量:当前页码
let _pageNum = 0;
// 变量:用来存储上文所说的 bjyConnector 对象
let _object = null;
// 函数:递归翻页 & 截图 & 保存图片
function saveImage () {
if (!_object || !_object.goto) return
_object.goto(_pageNum, 1);
html2canvas(_domObj).then(canvas => {
let url = canvas.toDataURL('image/png')
downloadFileByA({from: url, to: 'PPT截图.png'})
_pageNum++
saveImage()
}).catch(err => {
// 当页码超过PPT的最大范围时,会抛出错误,这时将不再递归函数
console.log(err, '结束了')
})
}以上代码,我们可以放在控制台进行执行,执行的步骤如下:
// 步骤0:执行上述代码进行变量和函数声明
// 步骤1:加载html2cavas.js文件
loadScript('https://cdn.bootcdn.net/ajax/libs/html2canvas/1.4.1/html2canvas.min.js')
// 步骤2:在 notifyClick 函数中打上断点,并将 bjyConnector 对象保存到全局变量(此处,假设浏览器保存的全局变量名为 temp1)
_object = temp1
// 步骤3:运行递归函数启动“递归翻页 & 截图 & 保存图片”流程
saveImage()文章为用户上传,仅供非商业浏览。发布者:Lomu,转转请注明出处: https://www.daogebangong.com/articles/detail/jie-tu-xia-zai-wang-ye-zhong-de-PPT.html
 支付宝扫一扫
支付宝扫一扫 
评论列表(196条)
测试