计算机最初设计的目标是进行数值计算,最早在计算机中表示的数据是各种数字信息。随着应用逐渐广泛,计算机数据也能够以各种形式展现,如:数字、文字、图像、声音和视频等。然而,这些数据在计算机内部仍旧以数字形式进行存储和处理。
通过使用数字将各种信息按照特定规则进行处理,最终转换为计算机能够理解的信息,这个过程称为数字化编码。即用最少量的基本符号,对大量复杂的信息进行规律性的组合。
编码的两个基本要素:
基本符号的种类(例如二进制的“0”和“1”)
组合规则
现代计算机内部采用二进制符号进行信息编码。
1 计算机中数据的表示方法
任何一个二进制数N都可以表示为
N=S·2^E
其中E是一个二进制整数,称为数N的阶码,2为阶码的基数,S是二进制小数,称为数N的尾数。E和S可正可负。尾数S表示数N的全部有效数据,阶码E指明该数的小数点位置,表示数据的大小范围。
2 整数的表示
整数是没有小数部分的整型数字。
例如:123、4、-56、0等都是整数,而1.34则不是整数。
计算机中整数的分类:
无符号整数:只存在正数的整数。
有符号整数:最高位表示正负的整数。
2.1 整数的原码、反码和补码
2.1.1 整数的原码
所谓原码是用一个数的最高位存放符号(0为正,1为负),后续的其他位与数的真值相同的数据表示方法。
2.1.2 整数的反码
用最高位存放符号,并将原码的其余各位逐位取反。反码的取值空间和原码相同且一一对应。
2.1.3 整数的补码
在补码表示法中,正数的补码表示与原码相同,即最高符号位用0表示正,其余位为数值位。而负数的补码则为它的反码、并在最低有效位加1所形成。
我们在使用程序设计语言设计程序中使用的是数据的原码,而数据在计算机中是以补码的形式存在的。
2.1.4 三种编码的比较
a 三种编码(原码、反码、补码)的最高位都是符号位。
b 当真值为正时,三种编码的符号位都用0表示,数值部分与真值相同。即它们的表示方法是相同的。
c 当真值为负时,三种编码的符号位都用1表示,但数值部分的表示各不相同,数值部分存在这样的关系:补码是原码的“求反加1”(整数),或者“求反末位加1”(小数);反码是原码的“每位求反”。
c 它们所能表示的数据范围基本一样。
区别:在于对负数的表示方法有所不同。
2.2 整数算术运算的方法
以补码的形式进行运算。
3 实数的表示
实数是带有整数部分和小数部分的数字。
例如:1.23、3.4、0.56等都是实数。
实数小数点位置不固定,所以称浮点数。它是既有整数又有小数的数,纯小数可以看作实数的特例。
在计算机中采用浮点表示法(通常采用IEEE754标准)来表示实数。
3.1 实数的格式
为了使表示法的固定部分统一,科学计数法(用于十进制)和浮点表示法(用于二进制)都在小数点左边使用了唯一的非零数码。这称为规范化。
计算机表示实数时,只存储实数的三部分信息:符号,指数,和尾数(小数点右边的位)。小数点和定点部分左边的位1并没有存储——他们是隐含的。
例如,一个实数1000111.0101规范化后变成为:2^6×1.0001110101,
在计算机中表示为:

符号——一个数的符号可以用一个二进制位来存储(0或者1)。
指数——指数(2的幂)定义为小数点移动的位数。其可以为正也可以为负。余码表示法(后面讨论)是用来存储指数位的方法。
尾数——尾数是指小数点右边的二进制数。它定义了该数的精度。尾数是作为无符号整数存储的。
为了让正的和负的整数都可以作为无符号数存储,计算机通常采用余码系统。在余码系统中,使用一个正整数(称为一个偏移量)加到每个数字中,用于把他们同一移到非负的一边。这个偏移量的值是2^(m-1)-1,m是内存单元存储指数的大小。
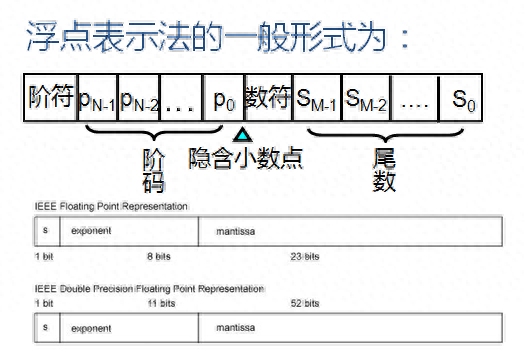
如32位计算机的偏移量:2^(m-1)-1=2^(8-1)-1=127
3.2 实数的算术运算
实数(浮点数)也可以进行包括加减乘除在内的算术运算。我们只介绍加法和减法,因为乘法和除法是加法和减法的多次重复运算。
浮点数加减法是同一个处理过程。步骤如下:
a 检验符号,如果符号相同,相加其值,结果符号与他们相同。如果符号不同,比较绝对值,绝对值大的减去小的,结果符号取绝对值大的一方。
b 移动小数点,使两者阶数相同。也就是说,当阶数不同时,数值小的一方将小数点左移,但要使值不变。
c 将变换后的数值进行加减运算(包括整数和小数部分)。
4 字符编码
随着现代计算机运用的深入,计算机不仅仅进行科学计算,实际上更大量的工作是用于处理人们日常工作和生活中最常使用的信息形式,也就是所谓的非数值型数据,包括语言文字、逻辑语言、视频图像等非数值信息。这需要为计算机找到一种合适的方法来表达这些信息。
计算机中使用了不同的编码来表示和存储数字、文字符号、声音、图片和图像(视频)信息。
编码(或代码)通常指一种在人和机器之间进行信息转换的系统(体系)。编码是人们在实践中逐步创造的一种用较少的符号来表达较复杂信息的表示方法。
4.1 ASCII码
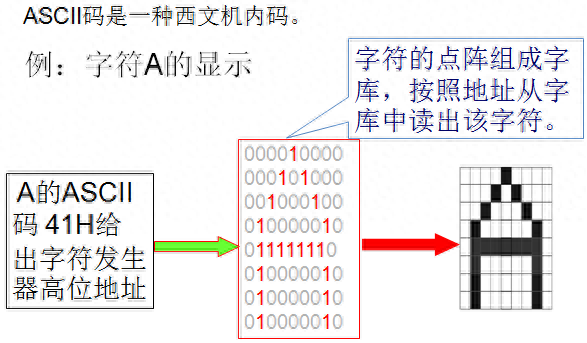
字符是非数值型数据的基础,字符与字符串数据是计算机中用得最多的非数值型数据。在使用计算机的过程中,人们需要利用字符与字符串编写程序、表示文字及各类信息,以便与计算机进行交流。为了使计算机硬件能够识别和处理字符,必须对字符按一定规则用二进制进行编码,使得系统里的每一个字母有唯一的编码;文本中还存在数字和标点符号,所以也必须有它们的编码。
1)ASCII码是使用最多和最普遍的字符编码,即美国信息交换标准代码(American standard code for Information Interchange)。
2)ASCII码有7位码和8位码两种形式 。
3)7位ASCII码:用七位二进制数进行编码的,可以表示128个字符,最高位恒为0。
4)8位ASCII码:用8位二进制数进行编码,可以表示256种字符;当最高位恒为0,与7位ASCII码相同,称为基本ASCII码;当最高位为1时,形成扩充ASCII码,各国一般把该码作为本国语言的字符代码。
5)键盘输入的数码0~9、52个大、小写英文字母A ~Z、a ~z、32个标点符号、运算符号、专用符号和34个控制符,采用7位ASCII码编码。
4.2 汉字编码
汉字也是字符,与西文字符相比,汉字数量庞大,字形复杂,同音字较多,这就给汉字在计算机内部的存储、传输、交换、输入、输出等带来了一系列挑战。为了能直接使用西文标准键盘输入汉字,还必须为汉字设计相应的输入编码,以适应计算机处理汉字的需求。
汉字信息所涉及的编码:
4.2.1 汉字输入编码
汉字输入通常有键盘输入、语音输入、手写输入等方法,每种方法都有其优缺点。键盘输入方式:将每个汉字用一个或几个英文键表示,这种表示方法称为汉字的“输入编码”。
汉字输入编码的种类:
数字编码:如电报码、区位码等。特点:难于记忆,不易普及;
字音编码:如拼音码等。特点:简单好学,但重码多;
字形编码:如五笔字型、表形码等。特点:重码少,输入快,但不易掌握;
音形编码:如自然码、快速码等。特点:规则简单,重码少,但难以掌握。
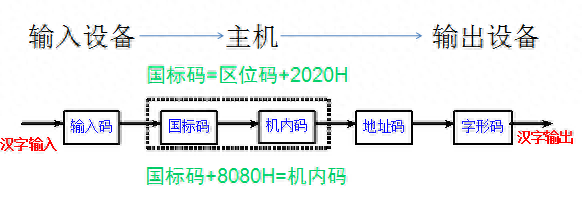
4.2.2 国际码和区位码
1980年我国发布了《信息交换用汉字编码字符集基本集》代号为GB2312-80,这是国家规定用于汉字信息处理的代码标准,称为国标码。在国标码的字符集中共收录了6763个常用汉字和682个非汉字字符(图形、符号),其中一级汉字3755个,以汉语拼音排序,二级汉字3008个,以偏旁部首排列。
所有汉字字符用2个字节表示,高字节共分为94个区(01-94区),低字节分为94个位(01-94位),汉字所在的区号和位号共同组合成该汉字的区位码,区位码为十进制。
非汉字图形字符排在01----15区;
一级汉字排在16---55区;
二级汉字排在56---87区;
例如:“中”区号54、位号48 ,区位码为5448
“国”区号25、位号90,区位码为2590
国标码的转换:将汉字的区位码表示成16进制,在加上2020H。
即:国标码=(区、位码)16+2020H
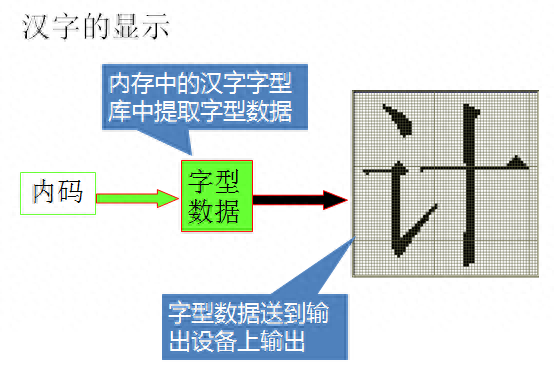
4.2.3 机内码
汉字的机内码是计算机系统内部对汉字进行存储、处理、传输统一使用的代码,又称为汉字内码。汉字内码是与ASCII对应的,用二进制对汉字进行的编码。
一般用2个字节来存放汉字的内码,即双字节字符集(double-byte character set,简称DBCS)
4.2.4 矢量、点阵输出输出码
矢量方式存储的是描述字体的轮廓信息。
点阵是对汉字字形经过点阵数字化后的一串二进制数,又称为汉字字形码或字模。
一般显示用16×16点阵,打印用24×24、32×32、48×48等点阵。
点阵越多,打印的字体越好看,但占用的存储空间也越大.
4.2.5 汉字的整个处理过程
4.3 Unicode码
尽管ASCII码在字符编码领域占据重要地位,但其他更具扩展性的编码也逐渐广泛应用,这些编码可以表示各种语言的文档资料。其中之一是Unicode,由多家硬件及软件主导
文章为用户上传,仅供非商业浏览。发布者:Lomu,转转请注明出处: https://www.daogebangong.com/articles/detail/ji-suan-ji-zhong-shu-zi-wen-zi-tu-xiang-sheng-yin-he-shi-pin-de-biao-shi-yu-bian-ma.html
 支付宝扫一扫
支付宝扫一扫

评论列表(196条)
测试