
关注我可以获取更多骚操作和脑洞哦
超久没写推送了orz
最近实在是太忙了
拍好的胶卷都没洗
Pr教程可能要停更一会儿
又是一个爆肝的学期。一周两节实验课,四篇实验报告实在是让人头疼和心累,你可要知道,我们的实验报告是要用手写的!!

一次肝实验报告我突生一个想法:如果把自己的写的字做成字体,以后再要手写什么都不怕了!
这真的是一个骚操作啊~

于是,我决定,做一个属于自己的字体!
我们知道在windows和macOS中安装的字体通常是以ttf字体(True Type Fonts)为主,于是我就开始在搜索引擎上疯狂搜索ttf文件的编码机制和文档。遗憾的是,相关的资料实在是太少了,看来手动编写ttf字体的想法破灭了。
不能自己写代码,我用现成的软件还不成?
又在网上搜索了一会儿,找到了一个软件叫做Font Creator,软件功能也挺多,于是我就决定是用这个软件编写字体。
首先是字体的录入:

GB2312信息交换用汉字编码库
我们知道,汉字采用GBK编码,在Unicode中有相应的字符。为了满足生产生活需要,同时缩小字体制作的工作量,一般的字体都采用GB2312标准制作。这个标准中包含6763个汉字、682个非汉字图形字,是1980年由国家标准局提出的信息交换用汉字编码字符集。GBK标准对GB2312中的所有内编码标准兼容,同时在字汇上支持ISO/IEC10646-1和GB13000-1的全部CJK汉字,共计20902个字。
GB2312相对其他标准(如GB13000)所包含的字汇较小,实用性强。其包含了3755个一级汉字和3008个二级汉字,其收录的汉字占中国大陆区域汉字使用频率的99.75%,是个人字体设计的最佳标准。当然对于一些人名和古文,GB2312可能稍有不力,催生了之后GB 18030汉字字符集的出现。

好了,让我说一些人话,接下来要做的就是要把这6763个汉字录入到电脑中,再用Font Creator这个软件导入字形图片,处理为字体。
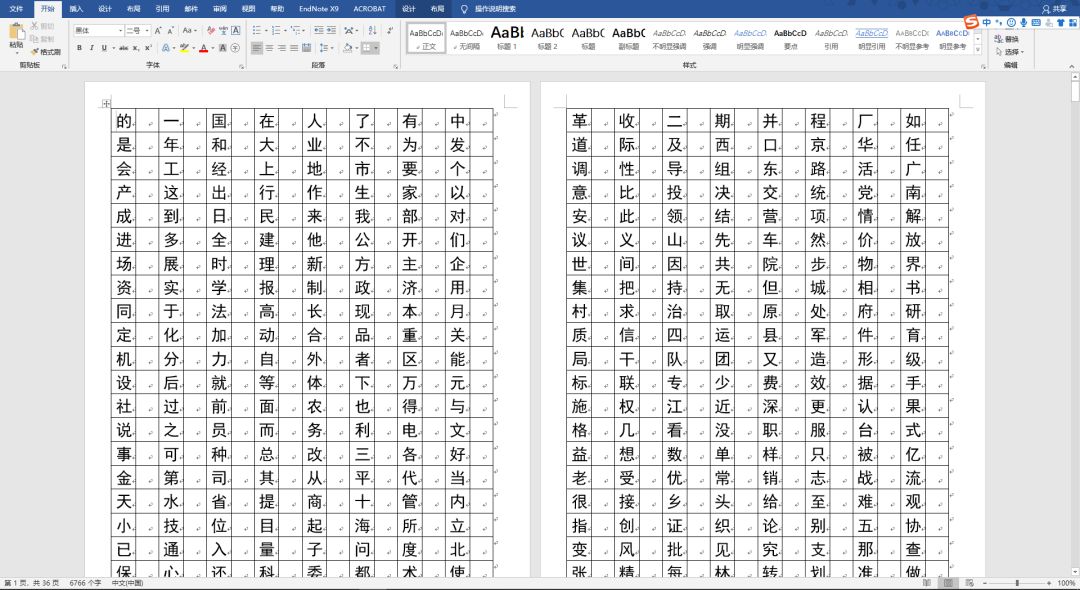
用Word做好的GB2312汉字库

首先我找到了GB 2312的全部6763个汉字的文件,随后我想到了考试答题卡用机器扫描读取的方式批改,于是我决定设计一个“答题卡”,将汉字写在对应的区域,由扫描仪扫描成图像,再用电脑识别并切割为每个单独的汉字。
利用Python强大的数据处理能力,用七十多行代码轻松完成了分割图片的工作,具体实现原理如下:
from PIL import Image
import os
import cv2
import imutils
from imutils.perspective import four_point_transform
def cut_edge(img_file):
image = cv2.imread(img_file, 1)
# 自适应二值化方法
blurred = cv2.GaussianBlur(image, (5, 5), 0)
edged = cv2.Canny(blurred, 50, 150)
cv2.imshow('', edged)
cv2.waitKey(1000)
# 从边缘图中寻找轮廓,然后初始化轮廓
cnts, hirerachy = cv2.findContours(edged,
cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
docCnt = None
# 确保至少有一个轮廓被找到
if len(cnts) > 0:
# 将轮廓按大小降序排序
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)
# 对排序后的轮廓循环处理
for c in cnts:
# 获取近似的轮廓
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# 如果近似轮廓有四个顶点,那么就认为找到了答题卡
if len(approx) == 4:
docCnt = approx
break
paper = four_point_transform(image, docCnt.reshape(4, 2))
cv2.imwrite(img_file, paper)
file_dir = '/ManualScript/'
files = os.listdir(file_dir)
file_list = []
for _ in files:
file_list.append(file_dir + _)
files = file_list
is_cut = input('是否裁剪:(Y/N)?
')
if is_cut.lower() == 'y':
for _ in files:
cut_edge(_)
label_file = r'text.txt'
with open(label_file) as f:
labels = f.readlines()
for _ in labels:
_ = _.strip()
H = 268.69
W = 179
w_0 = 11.6
h_0 = 0
dw = 22.4
dh = 11.2
w = 10.45
h = 10.9
for img_file in files:
i = 1
number = int(img_file.split('/')[-1].split('.')[0])
img = Image.open(img_file)
img_size = img.size
a = img_size[0] #图片宽度
b = img_size[1] #图片高度
for y in range(24):
for x in range(8):
index = (number - 1) * 8 * 24 + i
img.crop(((w_0 + x*dw + 0.1)*a/W, (h_0 + y*dh + 0.1)*b/H, (w_0 + x*dw + w)*a/W, (h_0 + y*dh + h)*b/H)).
save('/已分割/{}.jpg'.format(labels[index].strip()))
i += 1
使用Python编写的图片切割代码,左右滑动查看
图片读入-灰度转换-高斯模糊-二值化-指认边缘-坐标读取-四点变换-字位识别-图片切割-生成单字图片。
然而opencv的库并没有想象中那么友好,运行代码就Traceback,居然来自库内的cpp文件报错,仔细检查代码、输入的图片文件都没有发现问题。
debug半小时之后,我发现连imread函数的对象都是空的,因此我怀疑是图片读取有问题。改加去转义符r和正斜杠仍然报错,最后发现居然不支持中文路径。
Debug完了之后,代码就正常工作啦,一张张写满字的表格被切割成一个个字。再稍微微调了一下程序切割边界,讨厌的框框也基本上没了。


切割完的单字图片,残留边框基本被剔除

下面就是将字形图片导入Font Creator。真不巧,这个软件居然只能一个个手动导入,可能写软件的人只想到西文字体设计吧(手动导入6千多个字符也太傻了吧)。
当然不能手动!我拿出了深藏多年的骚操作:按键精灵。这个脚本功能实在是太强大了,可以模拟鼠标、键盘动作和系统操作,还能读取文件。
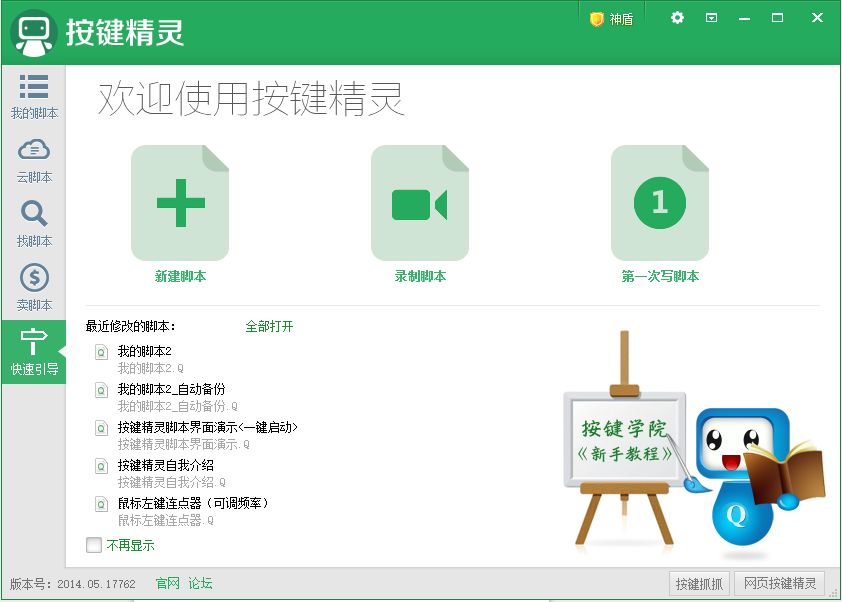
不得不说这个脚本的编写过程很像写Turtle,全程MoveTo

随后就是微调和运行程序等待结果。
弄了一个多小时,陆陆续续把3500个字录入进去了。
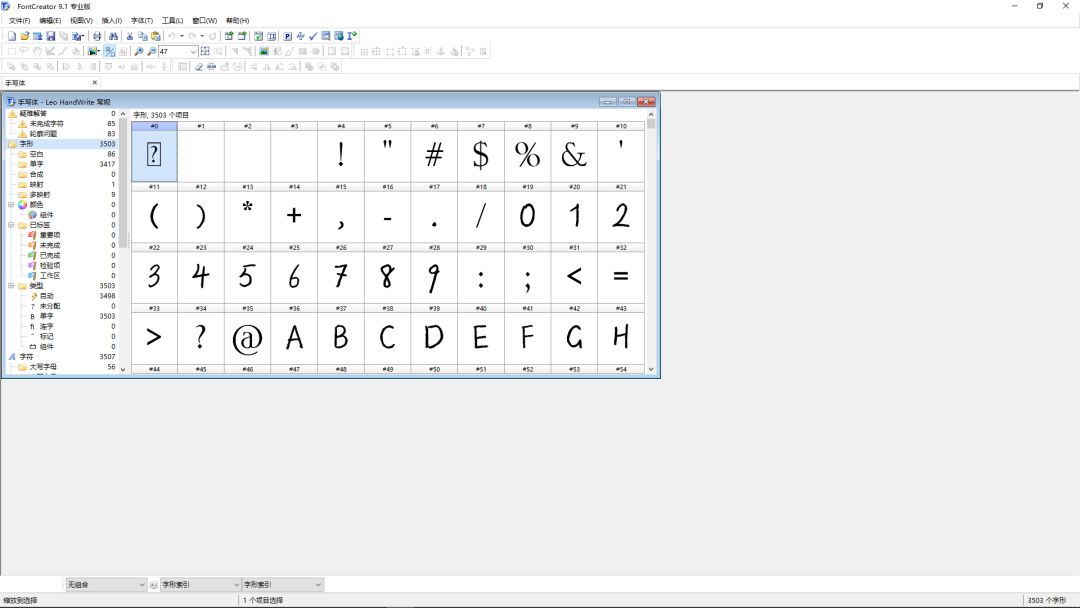
接下来就是调整字的大小、行距、字距、左右边界、上下位置。
幸运的是,我在软件里找到了相应的批量脚本,自动运行,实在是太爽了。
调整字的上下位置时,不能将所有字的最下边界对齐,而是应该将字的视觉重心对齐,这样显示出来才不会显得不自然。字的大小也应该有差异,在这一点上,我保留了原来在纸上书写的相对大小。
做完了一番调整之后,我又把符号做了,然后测试了一下字体,看起来棒极了!
考虑到字频,我先做了3750个字,剩下的3000字再慢慢写。
为了模拟出真实情况,我故意把一些字写错,打印出来之后再用笔划掉它们改成正确的,模仿出写错字的情况。Opentype字体貌似还可以有一些随机连笔算法,可以让书写变得更加真实,我还在研究中。

最终的效果如下:
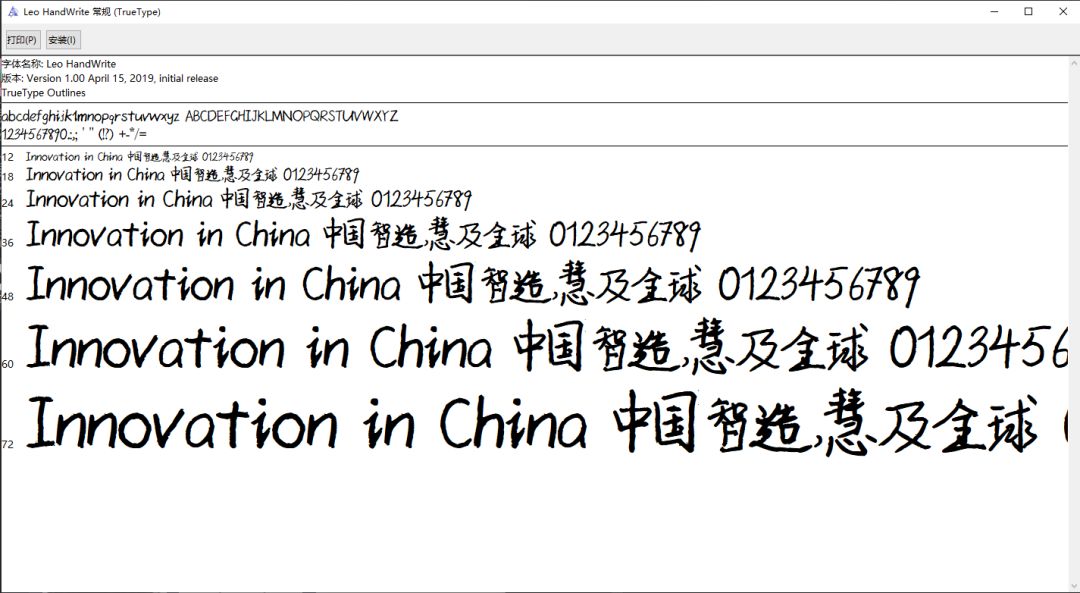
我先是用了一些文本测试了一下,比如莎士比亚的哈姆雷特片段:

然后我又把我之前的实验报告给换成手写字体:


哈哈哈哈哈哈哈哈像不像手写的?!
虽然在我做完字体之前就写完了这学期的所有实验报告(

然而word并不能显示我的字体,这让我很沮丧,又调试了一下,莫名其妙就可以了,但是在下一个版本的字体中word仍然不能显示我的字体,汉字全部变成了一个个方格。在仔细研究了字体文件的编码之后,我发现在字体生成的时候需要规定其Unicode字符范围,将字符范围选择为CJK和其他必要的符号即可让汉字显示,并且,还需要将字体设置为“拉丁文手写”,否则word不能将其识别为可使用的字体。(如果设置为拉丁文印刷体,字体将变为等宽字体,导致部分重叠)。
解决了字体显示问题之后,我发现在word里面并不能直接输入该字体,而是需要通过将已经写好的文本的字体设置为拉丁文手写体才能生效。
然而拉丁文手写体好像也不稳定,最后把字体Panose设置成“不适合”
弄到最后发现其他电脑都没问题就我的不行,怕不是个假的word...
想要属于自己的字体吗?
我会根据情况决定要不要做一个字体制作教程~快来投票吧:
文章为用户上传,仅供非商业浏览。发布者:Lomu,转转请注明出处: https://www.daogebangong.com/articles/detail/have%20your%20own%20handwritten%20font.html
 支付宝扫一扫
支付宝扫一扫 
评论列表(196条)
测试